
SEPTEMBER 2023 RELEASES
September 2023 Releases
When teams design AI agents, the hardest part usually isn’t deciding what information to collect. It’s deciding when to collect it, and how much context the agent needs before deployment.
An AI agent doesn’t experience a conversation all at once. During a live call, it only knows what’s been said so far. After the call ends, it can finally see the full arc of the conversation: what the contact cared about, how objections evolved, and what outcome makes sense going forward.
Regal is designed around that reality. In this article, we’ll discuss how you can leverage real-time decision-making and post-call analysis to increase personalization in your customer interactions, evaluate your agent long-term, and extract insights for continuous improvement.
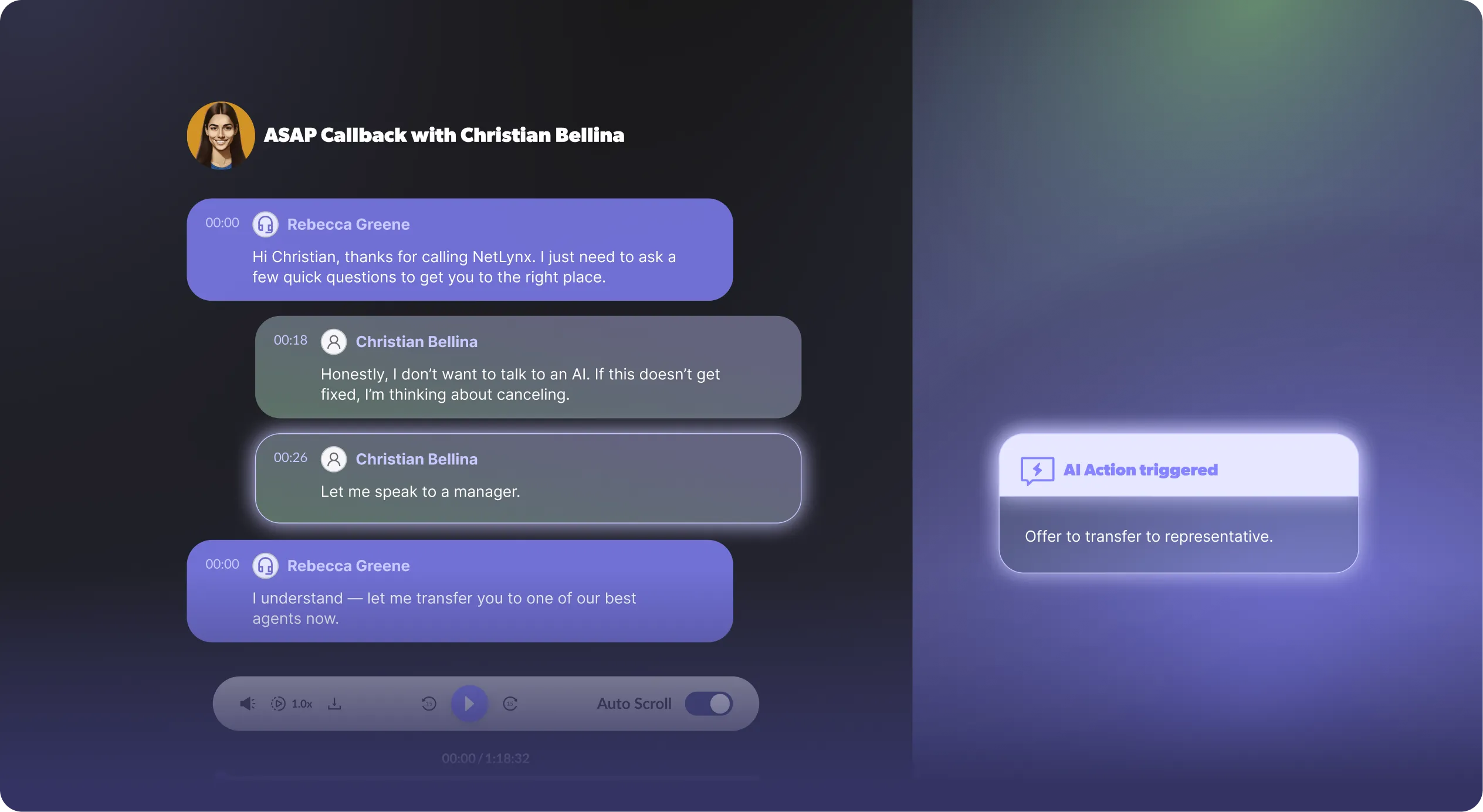
In live customer conversations, timing is everything. The most valuable signals—frustration, intent to cancel, requests for escalation—don’t appear neatly at the end of a call. They happen in the moment, when the customer’s experience is being shaped. AI Actions make it possible to capture and act on these signals as they occur, enabling you to collect the right data at the right time and respond in ways that protect customer trust and business outcomes.
Imagine an AI agent handling an inbound qualification call. Early in the conversation, the contact becomes frustrated and says, “I don’t want to talk to an AI. Let me speak to a manager” or explicitly asks to cancel.
This is a decision point that changes the live call experience. Waiting until the call ends to act would risk frustrating the customer further, or even losing them forever.
That’s where AI Actions come in.
AI Actions allow an AI agent to trigger structured, predefined operations during a live conversation while the call is still happening, rather than just talking to a customer at the moment. For example, the AI agent can trigger an escalation, transfer the call to a human, update an external system, or emit a signal that something important just occurred, all in real-time.
In the above example, you can configure the agent to validate the contact’s frustration, and either try to contain the conversation for a bit longer (i.e., “I’d be happy to connect your to a human representative after collecting some more information”) or in more sensitive cases, call a transfer action to escalate right away. This realtime reaction signals to the contact that their concerns are heard, and acted upon.
Importantly, these actions don’t disappear after the call. Every Custom Action invocation is recorded in the transcript, which means it becomes part of the permanent call record and can be analyzed and reported on later.
.webp)
Once the call ends, a different class of questions becomes possible.
Now we’re no longer asking, “What should the agent do right now?” We’re asking questions like:
These answers depend on the entire conversation, not a single moment. To answer these questions, you’ll require a nuanced understanding of not only what was said on the call but the contact’s engagement, interest, and needs. With Custom AI Analysis, you can easily capture these fuzzy signals to evaluate the call’s outcome and success, and personalize future outreach.
With Custom AI Analysis, you can define a set of structured data points (i.e., interest, frustration, use case) to be automatically extracted via LLM from the full post-call transcript. These results are emitted in the `call.analysis.available` event and can be used throughout Regal to trigger Journeys, update contact profiles, schedule future tasks, or drive downstream reporting.
For example, an insurance carrier can set up Custom AI Analysis data points across all discovery calls to extract each prospect’s primary question, objection, and readiness to buy. By analyzing full transcripts holistically, Custom AI Analysis can surface patterns that aren’t obvious from individual calls, such as frequent confusion around deductible structures for a specific policy. These insights can inform how your agent addresses the most common points of friction moving forward to maximize containment and conversion.
Unlike prompt AI actions, Custom AI Analysis is triggered after the call is over, so it benefits from maximum context. It’s best suited for nuanced classification and outcome decisions where meaning emerges over time, not in a single utterance.
Not every question you want to answer is about the contact. Some questions are about the agent itself.
Did the agent follow the qualification script? Did it ask the required questions? Did it handle objections appropriately? Was the tone aligned with your brand?
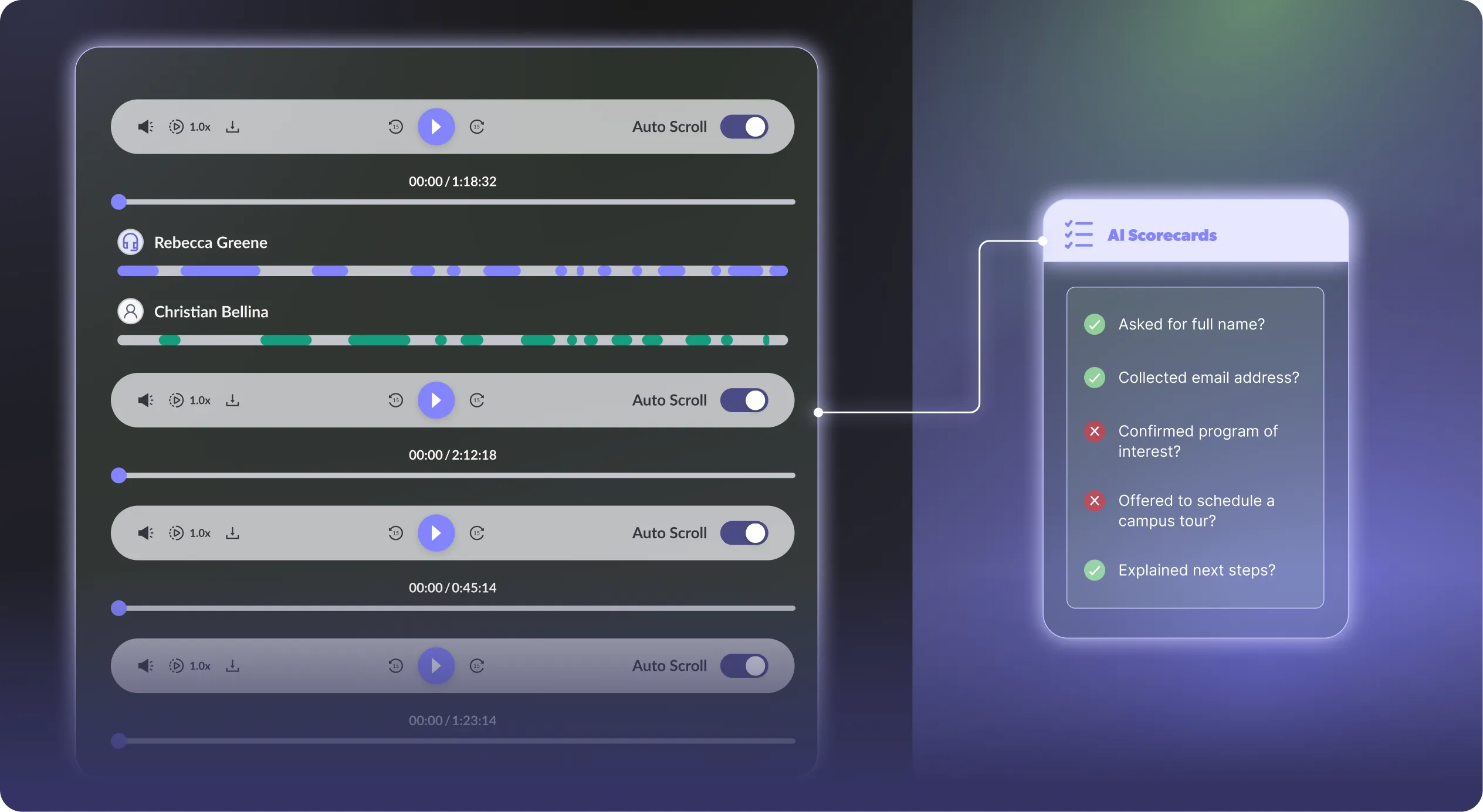
These are performance-focused questions, not outcome-focused questions, and AI Scorecards are designed to answer them.
AI Scorecards use LLMs to evaluate calls against success criteria you define, focusing on how the agent performed rather than what the contact decided. Scorecards make it easy to roll up insights across many conversations and identify trends in agent behavior without manually reviewing transcripts.
For example, a university admissions team can apply an AI Scorecard to inbound inquiry calls to evaluate whether AI agents followed the required tour-booking process. The scorecard automatically validates whether the agent asked for the student’s full name and email, confirmed their program of interest, offered to schedule a campus tour, and clearly explained next steps. By scoring every call against the same criteria, the team can quickly identify gaps in execution.
Since the evaluation is performed by an LLM, no manual transcript review or keyword searching is required. The model assesses agent performance using natural language understanding rather than rigid phrase matching, meaning it can recognize when an advisor offered to book a tour even if the wording varied from the script.
Scorecards also benefit from full-context visibility by evaluating the conversation after it ends. However, unlike Custom AI Analysis, the results are meant for quality assurance and iteration, not for driving contact-level actions.

Sometimes you don’t need a full interpretation of a call. When you’re troubleshooting a particular step in the agent script or validating the agent’s language to ensure appropriate messaging and tone, you just need to access a particular part of the conversation.
Moments are designed for this exact purpose. They identify and tag specific lines or segments of a conversation after the call ends, making it easy to search, filter, and audit conversations at scale without laborious or manual investigation.
Regal supports two types of Moments. Phrase-based Moments look for exact keywords or phrases for ensuring compliance language or required disclosures occurred. AI Moments go a step further, allowing you to describe a concept or provide examples in a text-based prompt, especially if you’re not sure exactly how it will be phrased (i.e., Did the contact mention they’re reviewing competitor solutions?). An LLM then tags parts of the conversation that match that description.
Moments operate at the level of individual points on the conversation timeline. They don’t attempt to classify the entire call or make outcome decisions. Instead, they make it easy to understand where certain topics appear and how often they occur.
The most effective AI agents don’t rely on a single data mechanism. They’re designed with the conversation timeline in mind:
If you’re ever unsure which tool to use, ask these questions:
By aligning data collection with when decisions should be made, you give your AI agents the structure they need to act intelligently, without forcing every insight into the same moment or mechanism.
Ready to optimize your AI agent decision-making? Schedule a demo with us.


.webp)
With AI agents, every appointment gets a confirmation call. Each contact gets a chance to reschedule, and the confirmation rate goes to 100%, not because the AI is better at conversations than your agents, but because the AI never runs out of capacity.

The fastest growing High Consideration brands have invested heavily in outbound call centers for sales and marketing. With the right technology, staffing and measurement, you too can build a high performing outbound call center to help hit your growth goals.
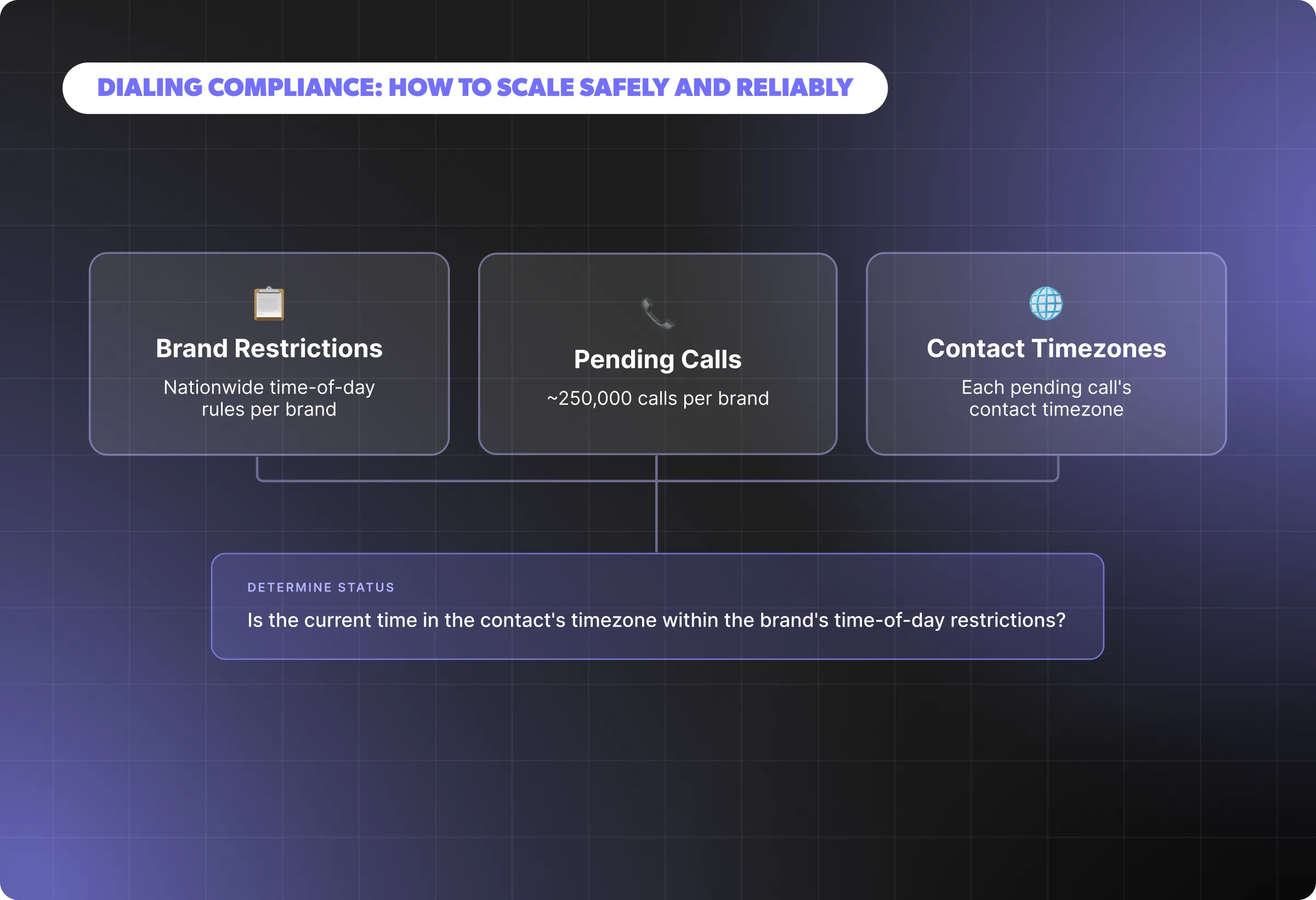
Behind a fragmented and ever-changing regulatory landscape is a simple goal: protecting people from unwanted or poorly timed outreach and giving them control over how they’re contacted. In practice, that responsibility translates into a set of checks that must be validated.

AI phone agents aren't just better phone trees. They are autonomous systems that can understand caller intent, retrieve relevant information from your CRM in real time, execute actions, handle objections and clarifications, and complete the conversation without human involvement.
.webp)
When prospects in healthcare and financial services hear "PII," they often imagine bulk data transfer: the idea that deploying an AI agent means copying a database somewhere. In most modern deployments, that's not what's happening.

In March, we made it faster than ever to build, launch, and continuously improve AI agents with Copilot, Regal's AI agent for building AI agents. Together, these updates lessen the time needed to launch and maintain agents, so you can focus on understanding your customers, unlocking new use cases, and driving faster business outcomes.
.webp)
AI agent performance depends on how well it aligns with real customer language, not just fluency. Regal Improve helps teams identify gaps and improve outcomes by analyzing real conversations and surfacing high-impact opportunities
.webp)
In this fireside chat, Regal Co-Founder & CEO Alex Levin sits down with Kin Insurance’s Austin Ewell and a360inc’s Henry Davidson to share how their organizations are using AI agents to transform outreach, customer experience, and operational efficiency. They discuss real-world deployments—from qualification and human agent handoffs to complex negotiation workflows—break down the results, and offer practical guidance for leaders adopting AI agents at scale.
.webp)
Learn about the difference between single-state and multi-state AI agents, and how each impacts speed, scale, and reliability. Discover when simplicity is enough and when enterprise workflows demand structured orchestration, so you can choose the right design for your use case.
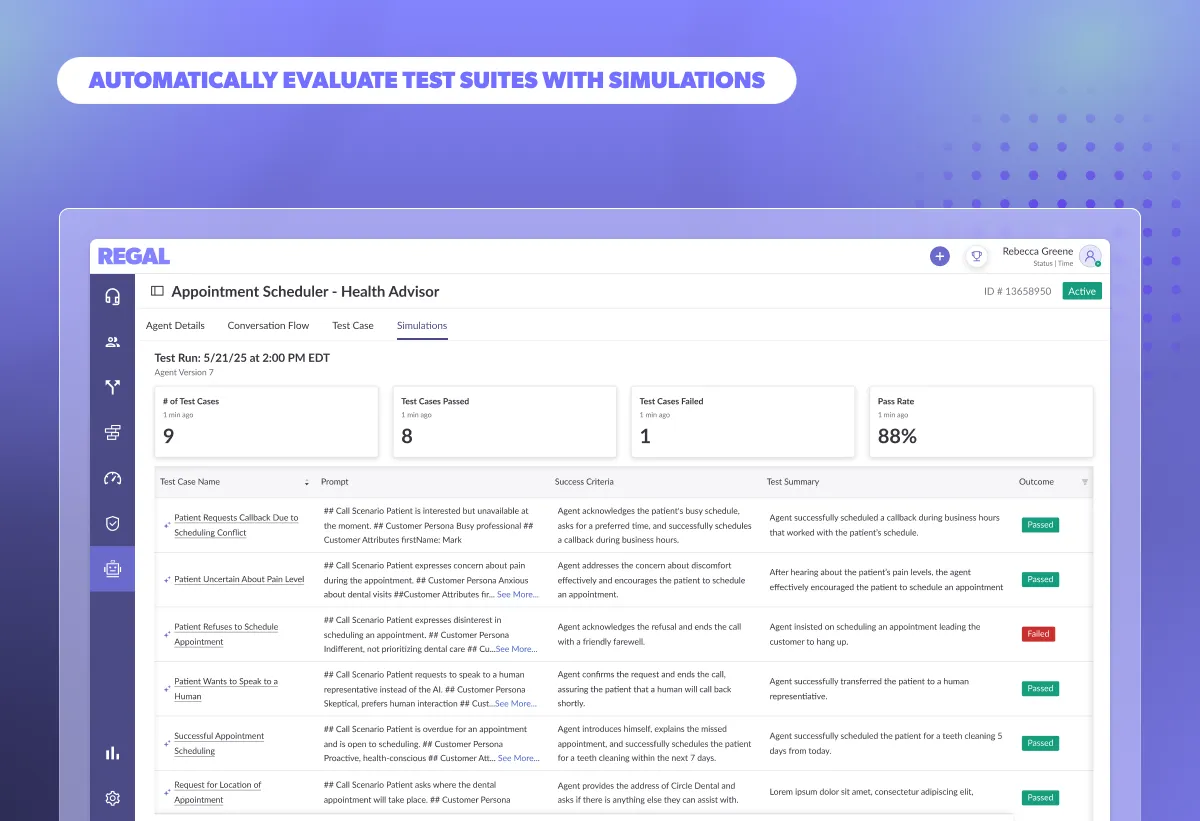
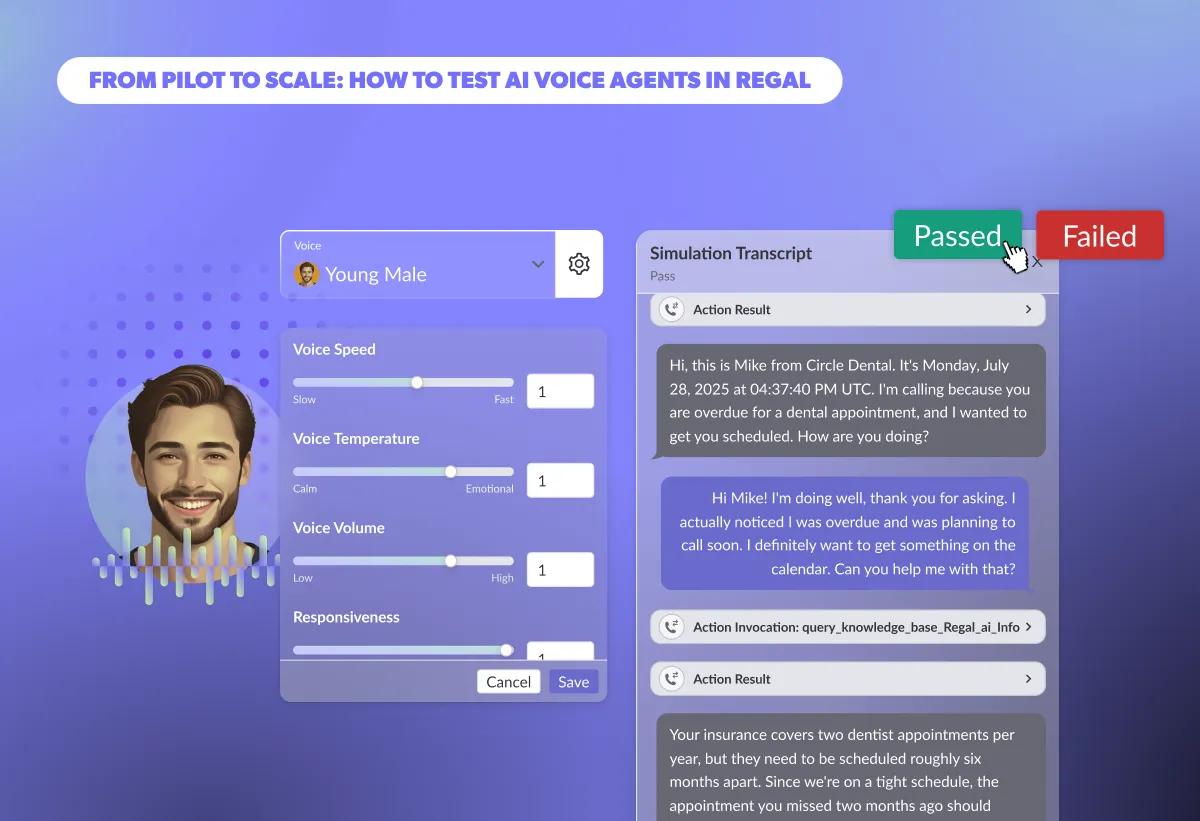
Discover how you can use Simulations to evaluate scenario-specific conversational flows that pinpoint AI Agent failures before launch. Speed up regression testing, validate prompts, knowledge bases, and custom actions at scale, and deploy reliable AI Agents with confidence.
%20(1).webp)
Apple’s iOS 26 introduces new call-screening controls that will reshape outbound performance. This guide explains what’s changing, how adoption may impact enterprise contact centers, and the proactive steps leaders can take now to protect answer rates and customer trust.
Learn how to maintain a clean, reliable RAG system for AI Agents. Discover best practices for structuring source docs, chunking content, titling for retrieval, avoiding redundancy, and keeping knowledge bases fresh to ensure accurate, scalable performance.
.webp)
This article outlines the core characteristics that influence how voice AI is perceived on live calls. From mechanical traits like speed and volume, to more emotional and conversational behaviors, we’re going to look at what those characteristics mean, why they matter, and how they impact your bottom line.
.webp)
Learn how to configure your AI Voice Agent for real performance. This guide covers the most important voice settings in Regal, what ranges top brands use in production, and how adjusting speed, tone, and responsiveness impact cost, containment, and overall customer experience.

AI Agents for Education are transforming student engagement—boosting enrollment, improving retention, and making support more human. Discover 8 game-changing use cases that free up your staff while delivering better student outcomes.

Regal is officially one of Forbes America’s Best Startup Employers 2025, ranking #164 out of 500. This recognition is a testament to our incredible team, our innovative work culture, and our unwavering commitment to advancing AI technology.

AI in education is helping to streamline admissions, automate student engagement, and enhance higher ed outreach. Discover key education technology trends to boost enrollment and learn why automated student engagement tools are the future.
.webp)
When it comes to comparing AI Agents vs. AI Assistants, Siri & Alexa handle simple tasks, but Gen AI Voice Agents—like Regal’s AI Phone Agent—drive real business impact with human-like conversations, automation, and seamless integration.

As AI technology continues to evolve, the use cases for AI Voice Agents in contact centers will only increase. By answering these six key questions, you can identify where AI agents fit best today in your contact center and plan for future integrations.

Consumer businesses are implementing AI-enabled customer experiences without any change in behavior on the part of consumers, which is leading AI to become common with more speed than past transitions like the internet and the smartphone. And it means that the next step in AI will not come from the LLM providers. The next big step forward in AI rests in the hands of consumer businesses.

Explore Eric Hauser's remarkable career journey from GovTech to healthcare disruption at Cadence, highlighting the transformative power of innovation, collaboration, with a special focus on the pivotal role of Regal in driving patient engagement and outcomes.

Discover how Regal.io's AI-powered personalized outreach solutions are revolutionizing outbound sales and customer experience across industries like healthcare, finance, and insurance in our latest eBook, "Modernizing Outbound Contact Centers: How to Treat Millions of Customers like One in a Million."
Ready to see Regal in action?
Book a personalized demo.




.png)


.webp)
.webp)
.webp)

.webp)
.webp)
.webp)
.webp)

.avif)


.webp)


.webp)


.webp)
.webp)

.webp)


%20(1).webp)
.webp)
%20(1).webp)
.png)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)
%20(1).webp)
%20(1).webp)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)

.webp)


%202.webp)


.webp)
.webp)
.webp)
.webp)











.avif)






