
SEPTEMBER 2023 RELEASES
September 2023 Releases
LLMs can only generate responses based on what they’ve been trained on. They have no built-in access to proprietary business logic, documentation, or contact-specific data.
Some of that can be solved through prompting.
To drive consistent, best-in-class AI experiences, however, prompting alone isn’t enough. You need a way to dynamically enrich agent context with hyper-relevant information—for any user, at any given time, without sacrificing performance.
That's where retrieval comes into play. Retrieval-Augmented Generation (RAG) further determines what your agent says and when, by dynamically pulling data from trusted, proprietary data sources.
Regal’s new Knowledge Base feature enables Retrieval-Augmented Generation (RAG) directly within the Regal platform, allowing Voice AI Agents to dynamically retrieve information from your internal databases at runtime.
So, instead of having to build and maintain massive prompts or custom API/ETL pipelines (which introduce latency, more failure points, and ongoing maintenance costs), you’re able to have AI Agents pull real context from your data, while preserving low latency, and lower costs, at any scale.
Regal’s Knowledge Base feature is a new capability that connects AI Agents to your proprietary data sources (product catalogs/documentation, policy docs, support guides, FAQs, etc.).
1. Agent-Level Knowledge Configuration
Each agent can have a customized set of Knowledge Base (KB). And each KB can be connected to more than one agent via the Regal platform.
2. Smart, Dynamic Retrieval
Retrieval is triggered dynamically at runtime. Regal invokes the KB only when needed, minimizing unnecessary context injection. This means tighter control, keeping standard call flows clean and performant.
3. Optimized for Relevance and Speed
Retrieval is powered by vector-based search using Amazon Bedrock. The system fetches only the most contextually relevant chunks, which keeps response time low and improves answer precision.
Responses can be further guided by the guardrails and logic defined in your prompts.
4. Flexible Data Ingestion
Knowledge can be ingested from web URLs, PDFs, DOC files, or raw long-form text. So you can centralize data from existing documentation without reformatting or writing new code.
For internal-facing resources like help docs, support wikis, or policy guides that evolve regularly, ingesting via URL allows Regal to periodically rescrape the source. This keeps your AI Agent’s knowledge up to date without requiring manual edits to the agent itself.
5. Context-Aware Usage
Each KB includes a structured usage description that informs the AI Agent when and how to use the content. This allows you to govern retrieval behavior, reducing the risk of hallucinations and improving consistency in how your agents apply the knowledge.
.webp)
The Regal Knowledge Base gives you a scalable way to inject proprietary knowledge into your AI Agents so they can deliver smarter, brand-aligned, compliant conversations, without relying on bloated prompting or custom integrations.
Here’s what the feature enables:
Because KB content is separate from the prompt, your agent’s tone and logic stay tight, even as you scale up the knowledge they use on calls.
Regal AI Agents fetch answers in real-time, while always reverting to the correct source of truth.
RAG enables us to determine when the LLM should or should not be relied on. When the answer requires a more grounded or branded response, we never rely on the LLM.
This allows agents to handle everything from lightweight inquiries, to complex, regulated scenarios, ensuring every response is contextually accurate, brand-safe, and compliant.
Decoupling the KB from the prompt keeps token size small, which leads to faster LLM responses and lower processing costs (while still allowing you to prompt and build guardrails as strictly as you’d like).
Whether it’s answering product FAQs, scheduling appointments, or resolving policy-related questions, the RAG approach ensures that agents retrieve only the most relevant knowledge based on the specific context of the contact and the call itself.
If a contact is based in California, for instance, the AI Agent can pull California data only, referencing legislation, product availability, and other FAQs. It keeps conversations compliant, targeted, and useful.
Regal’s Knowledge Base feature is ideal for use cases where the AI Agent must reference detailed, dynamic, or regulated content mid-call.
For short, predictable content, you can use prompting to dictate LLM responses. For scalable, more dynamic information, use a Knowledge Base.
Common Use Cases Include:
%20(1).webp)
Why It Matters for Your Business
RAG-based Knowledge Bases are a key enabler of real AI transformation, because they help:
With Regal Knowledge Bases, your AI Agents can now deliver more accurate conversations at scale, while giving your team full control over what’s being said.
You can configure Knowledge Bases directly inside the Regal Agent Builder. Here’s how:
Manually monitoring scripts and measuring containment rate (depending on the use case) will give you a good sense of whether or not the AI is effectively referencing your knowledge bases.
Tip: Start with 1–2 KBs per agent, and expand from there if needed. Tune from there based on call type and complexity.
See detailed instructions on how to add a Knowledge Base to Regal.
With Regal Knowledge Bases, you can scale your AI Agents with real data, without sacrificing speed, performance, or control.
Want help launching your first KB-backed agent? Book time with our team.


.webp)
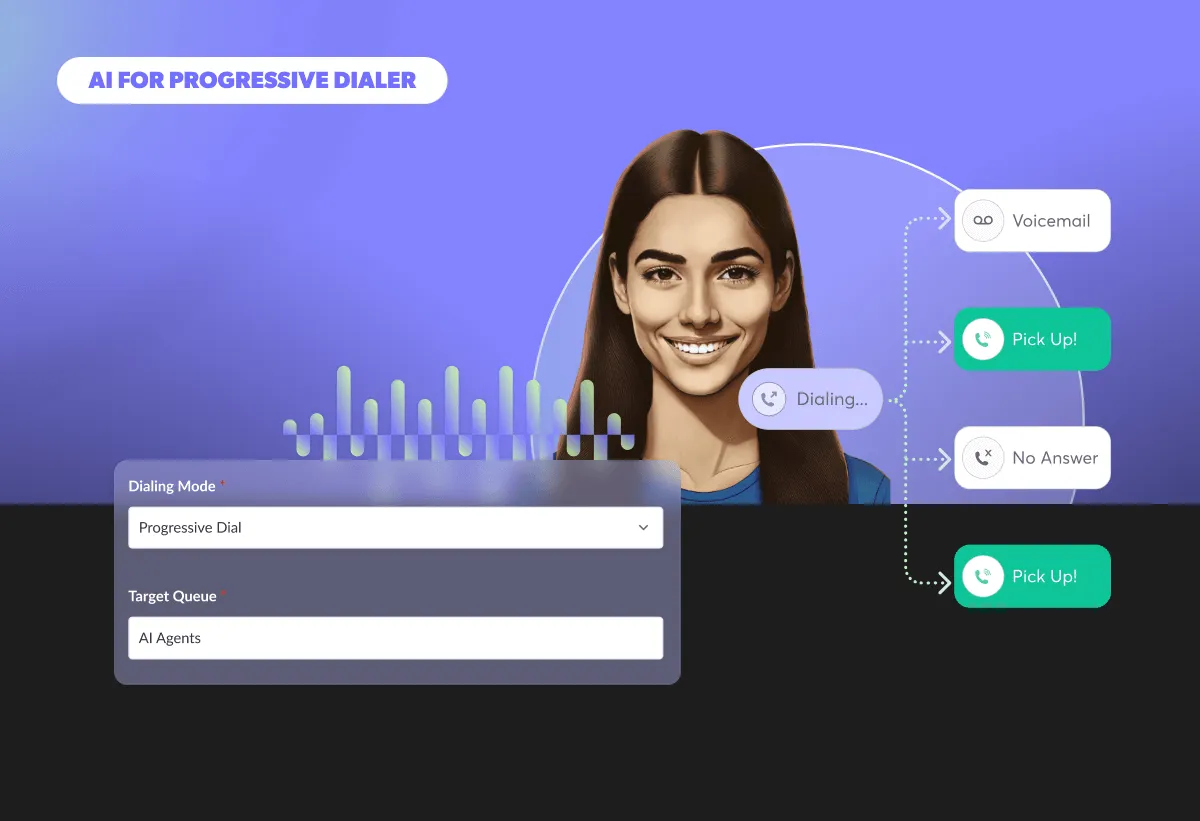
With AI agents, every appointment gets a confirmation call. Each contact gets a chance to reschedule, and the confirmation rate goes to 100%, not because the AI is better at conversations than your agents, but because the AI never runs out of capacity.

The fastest growing High Consideration brands have invested heavily in outbound call centers for sales and marketing. With the right technology, staffing and measurement, you too can build a high performing outbound call center to help hit your growth goals.
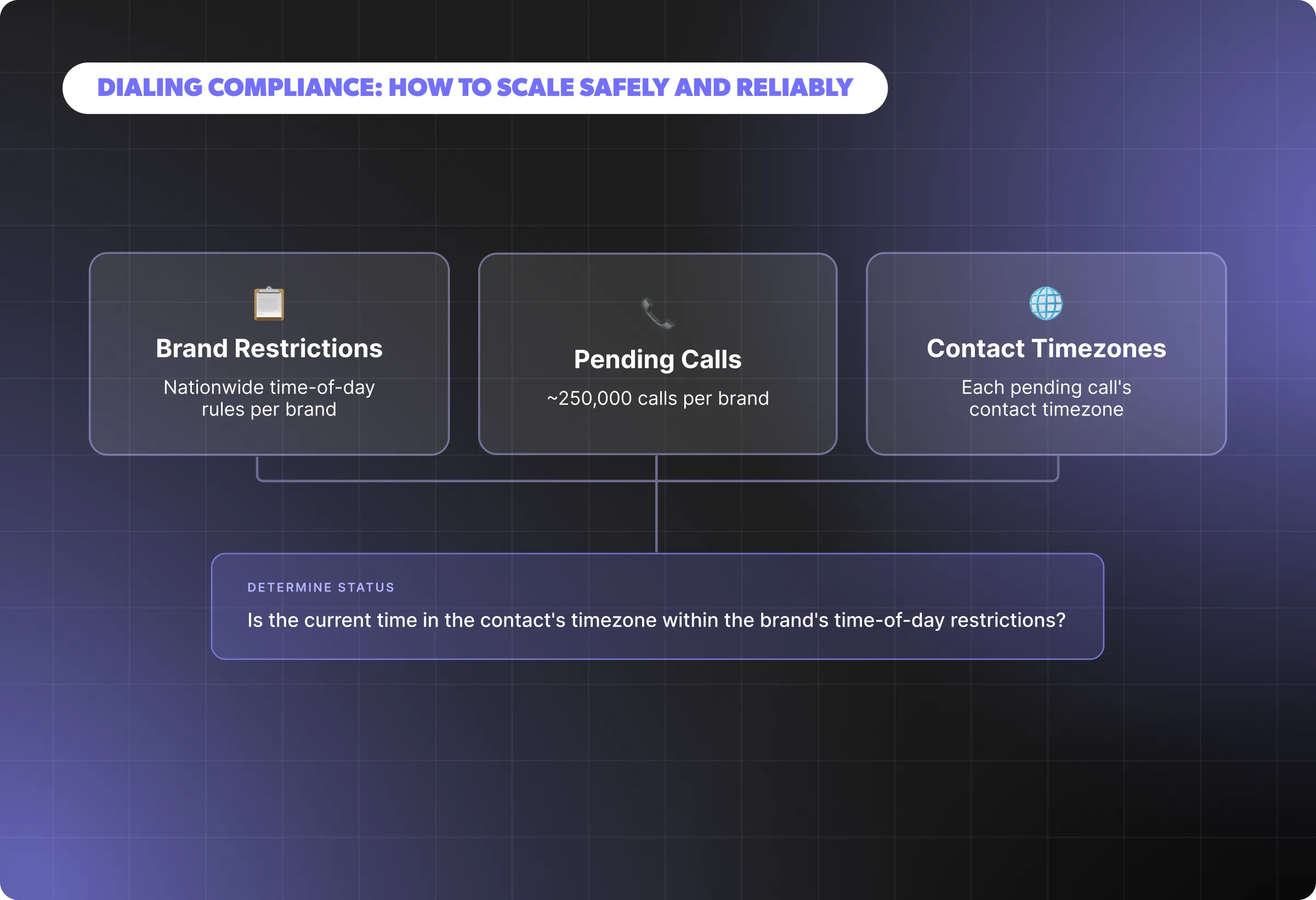
Behind a fragmented and ever-changing regulatory landscape is a simple goal: protecting people from unwanted or poorly timed outreach and giving them control over how they’re contacted. In practice, that responsibility translates into a set of checks that must be validated.

AI phone agents aren't just better phone trees. They are autonomous systems that can understand caller intent, retrieve relevant information from your CRM in real time, execute actions, handle objections and clarifications, and complete the conversation without human involvement.
.webp)
When prospects in healthcare and financial services hear "PII," they often imagine bulk data transfer: the idea that deploying an AI agent means copying a database somewhere. In most modern deployments, that's not what's happening.

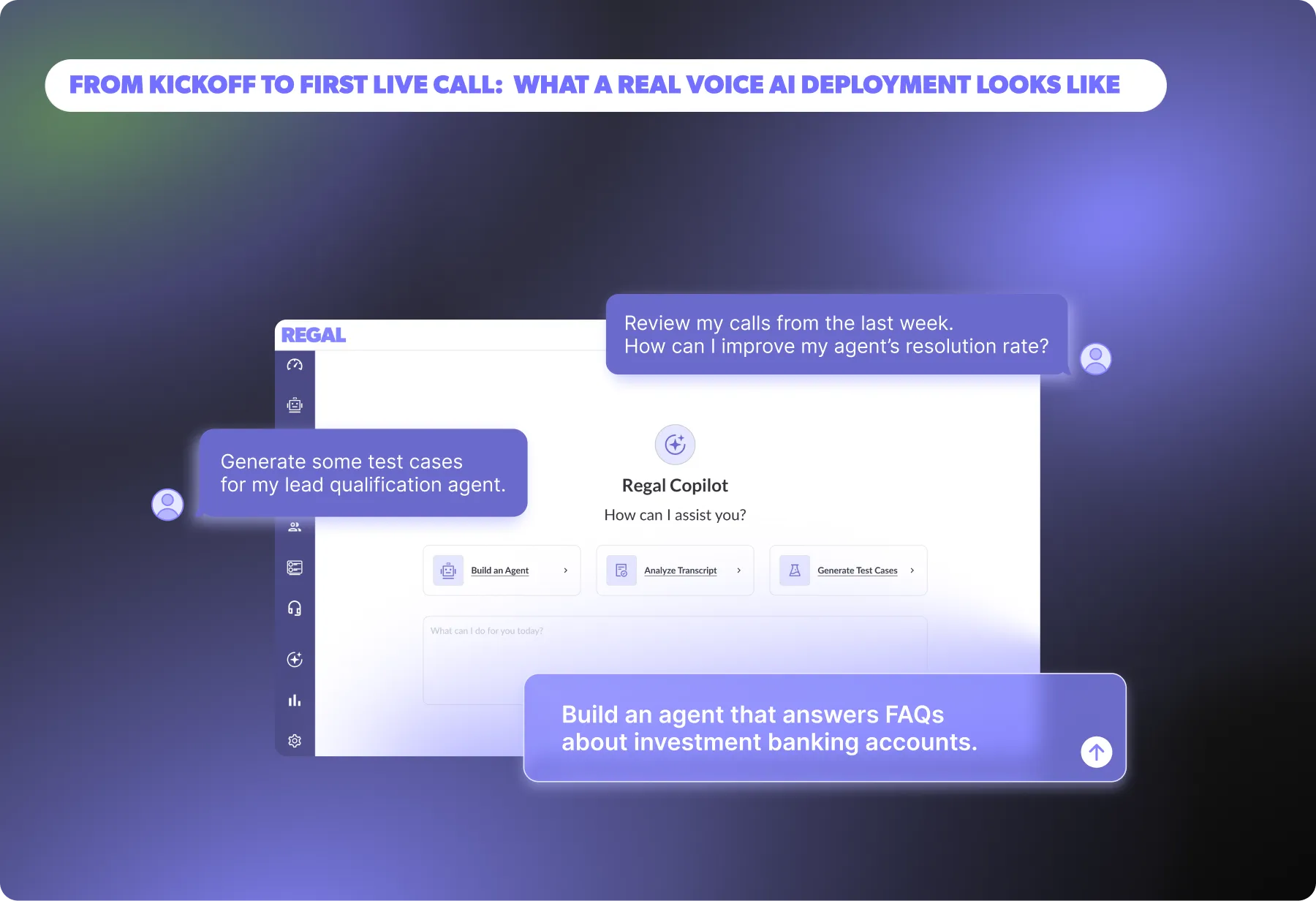
In March, we made it faster than ever to build, launch, and continuously improve AI agents with Copilot, Regal's AI agent for building AI agents. Together, these updates lessen the time needed to launch and maintain agents, so you can focus on understanding your customers, unlocking new use cases, and driving faster business outcomes.
.webp)
AI agent performance depends on how well it aligns with real customer language, not just fluency. Regal Improve helps teams identify gaps and improve outcomes by analyzing real conversations and surfacing high-impact opportunities
.webp)
In this fireside chat, Regal Co-Founder & CEO Alex Levin sits down with Kin Insurance’s Austin Ewell and a360inc’s Henry Davidson to share how their organizations are using AI agents to transform outreach, customer experience, and operational efficiency. They discuss real-world deployments—from qualification and human agent handoffs to complex negotiation workflows—break down the results, and offer practical guidance for leaders adopting AI agents at scale.
.webp)
Learn about the difference between single-state and multi-state AI agents, and how each impacts speed, scale, and reliability. Discover when simplicity is enough and when enterprise workflows demand structured orchestration, so you can choose the right design for your use case.
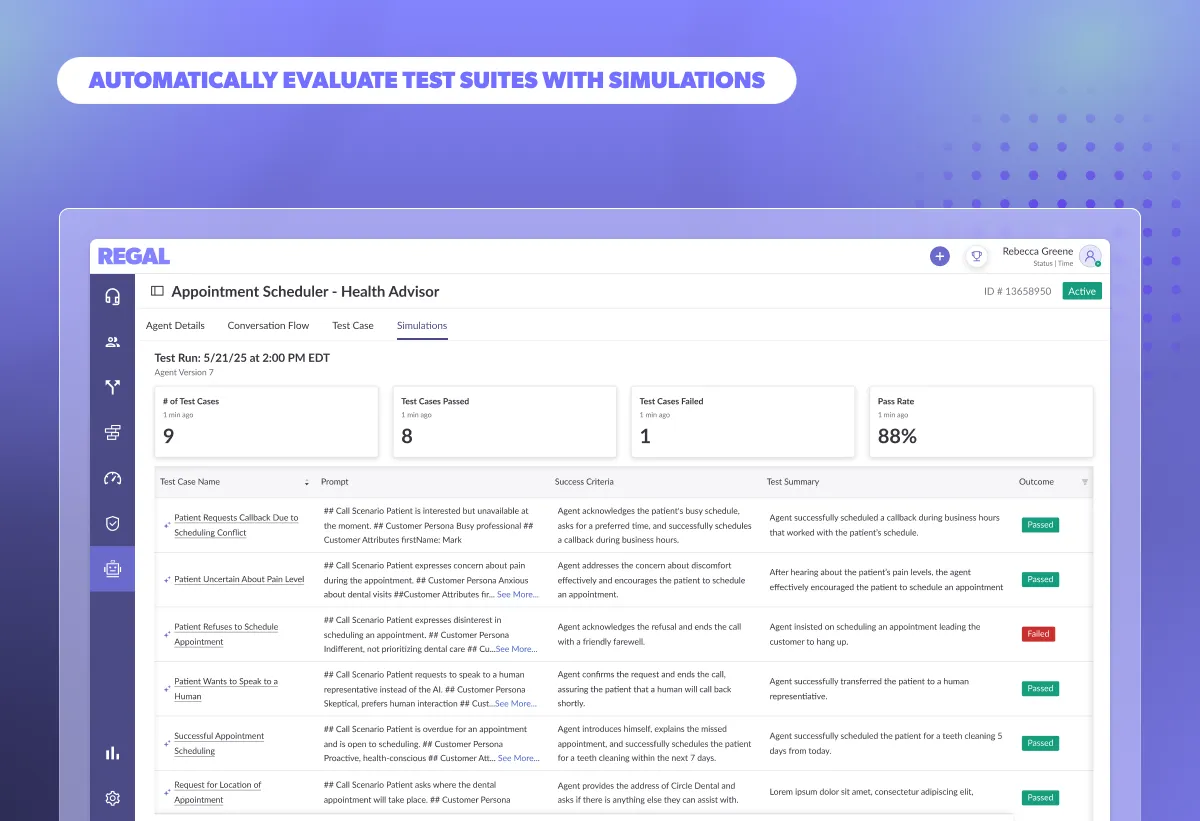
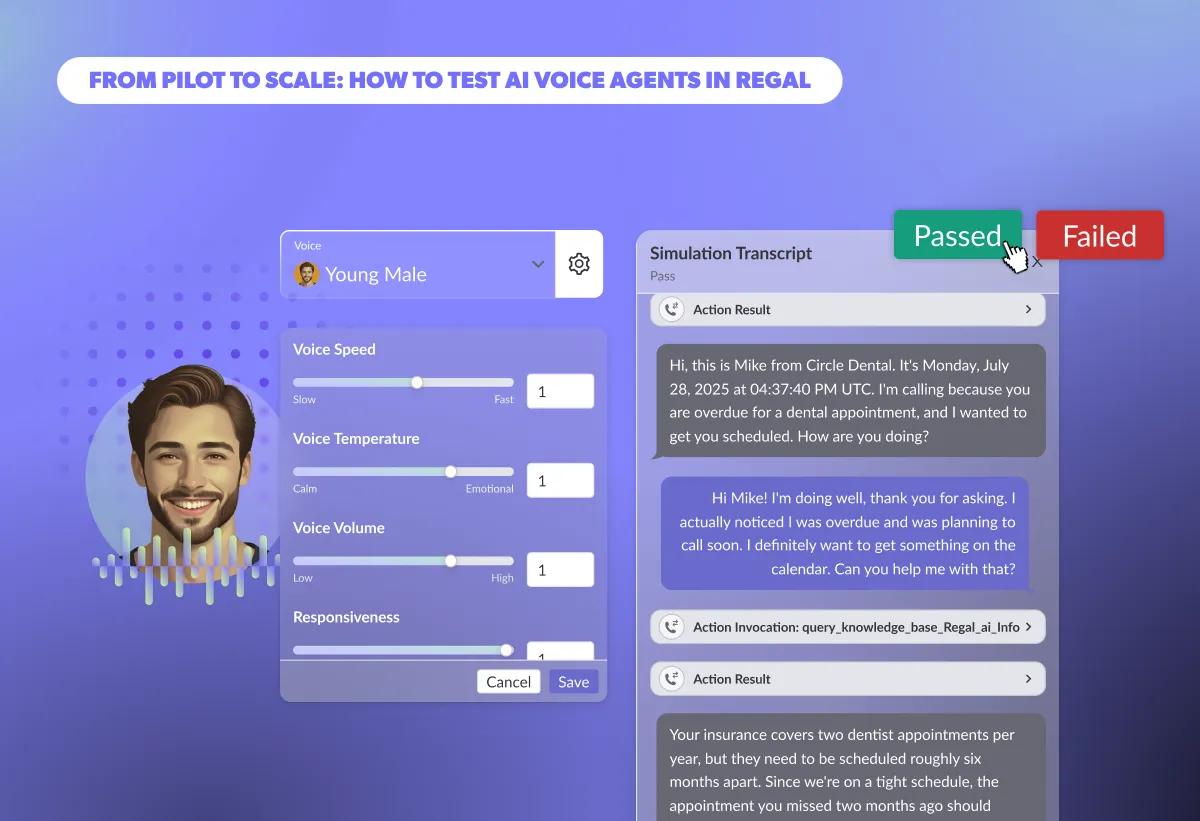
Discover how you can use Simulations to evaluate scenario-specific conversational flows that pinpoint AI Agent failures before launch. Speed up regression testing, validate prompts, knowledge bases, and custom actions at scale, and deploy reliable AI Agents with confidence.
%20(1).webp)
Apple’s iOS 26 introduces new call-screening controls that will reshape outbound performance. This guide explains what’s changing, how adoption may impact enterprise contact centers, and the proactive steps leaders can take now to protect answer rates and customer trust.
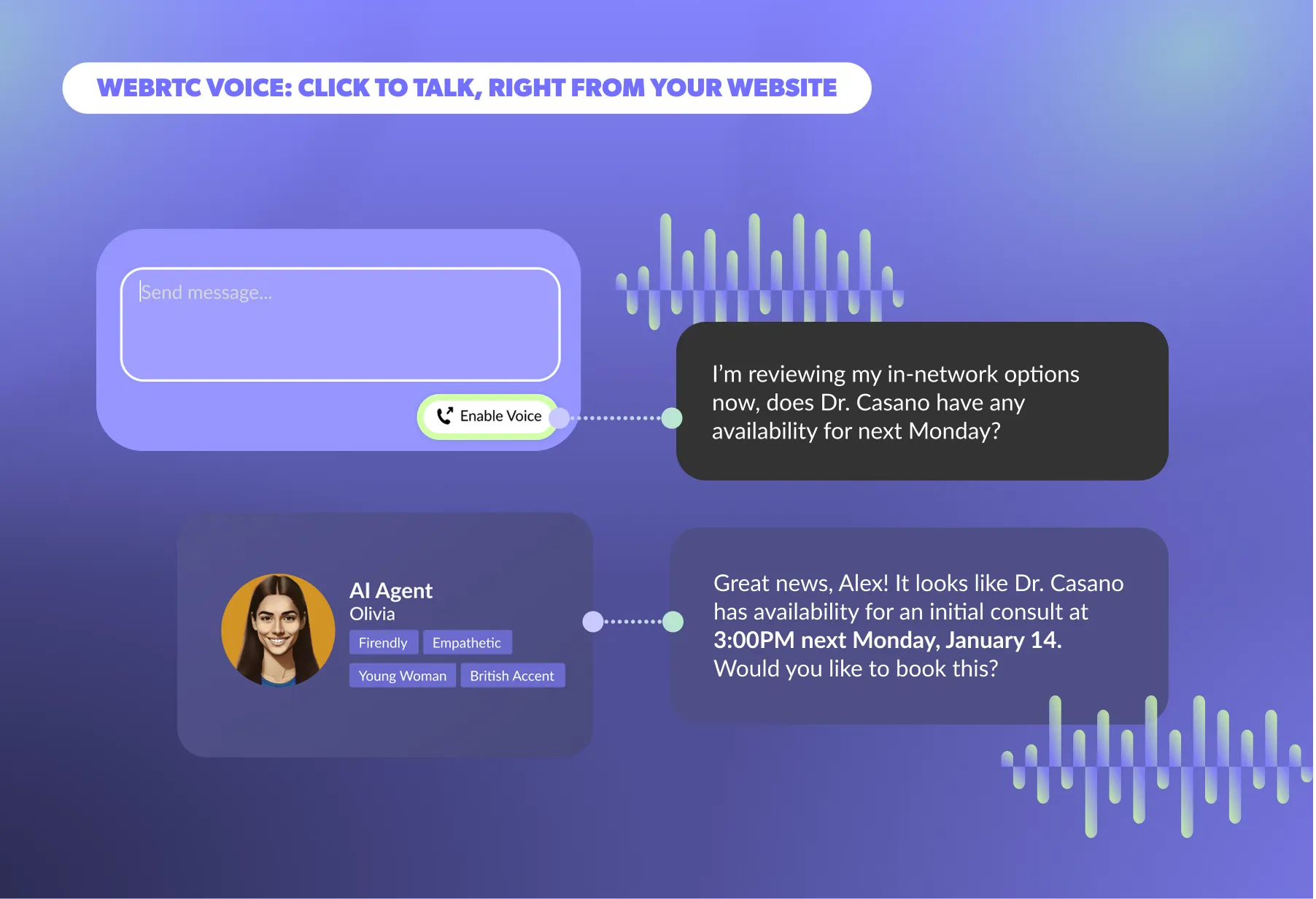
Learn how to maintain a clean, reliable RAG system for AI Agents. Discover best practices for structuring source docs, chunking content, titling for retrieval, avoiding redundancy, and keeping knowledge bases fresh to ensure accurate, scalable performance.
.webp)
This article outlines the core characteristics that influence how voice AI is perceived on live calls. From mechanical traits like speed and volume, to more emotional and conversational behaviors, we’re going to look at what those characteristics mean, why they matter, and how they impact your bottom line.
.webp)
Learn how to configure your AI Voice Agent for real performance. This guide covers the most important voice settings in Regal, what ranges top brands use in production, and how adjusting speed, tone, and responsiveness impact cost, containment, and overall customer experience.

AI Agents for Education are transforming student engagement—boosting enrollment, improving retention, and making support more human. Discover 8 game-changing use cases that free up your staff while delivering better student outcomes.

Regal is officially one of Forbes America’s Best Startup Employers 2025, ranking #164 out of 500. This recognition is a testament to our incredible team, our innovative work culture, and our unwavering commitment to advancing AI technology.

AI in education is helping to streamline admissions, automate student engagement, and enhance higher ed outreach. Discover key education technology trends to boost enrollment and learn why automated student engagement tools are the future.
.webp)
When it comes to comparing AI Agents vs. AI Assistants, Siri & Alexa handle simple tasks, but Gen AI Voice Agents—like Regal’s AI Phone Agent—drive real business impact with human-like conversations, automation, and seamless integration.

As AI technology continues to evolve, the use cases for AI Voice Agents in contact centers will only increase. By answering these six key questions, you can identify where AI agents fit best today in your contact center and plan for future integrations.

Consumer businesses are implementing AI-enabled customer experiences without any change in behavior on the part of consumers, which is leading AI to become common with more speed than past transitions like the internet and the smartphone. And it means that the next step in AI will not come from the LLM providers. The next big step forward in AI rests in the hands of consumer businesses.

Explore Eric Hauser's remarkable career journey from GovTech to healthcare disruption at Cadence, highlighting the transformative power of innovation, collaboration, with a special focus on the pivotal role of Regal in driving patient engagement and outcomes.

Discover how Regal.io's AI-powered personalized outreach solutions are revolutionizing outbound sales and customer experience across industries like healthcare, finance, and insurance in our latest eBook, "Modernizing Outbound Contact Centers: How to Treat Millions of Customers like One in a Million."
Ready to see Regal in action?
Book a personalized demo.




.png)


.webp)
.webp)
.webp)

.webp)
.webp)
.webp)
.webp)

.avif)


.webp)


.webp)


.webp)
.webp)

.webp)


%20(1).webp)
.webp)
%20(1).webp)
.png)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)
%20(1).webp)
%20(1).webp)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)

.webp)


%202.webp)


.webp)
.webp)
.webp)
.webp)











.avif)






