
SEPTEMBER 2023 RELEASES
September 2023 Releases
Your choice of LLM is an important architectural decision when building a Voice AI Agent.
The model you select determines how well the agent interprets customer input, follows instructions, handles ambiguity, and executes downstream actions like qualification, scheduling, or custom workflows.
While most agents begin with OpenAI’s GPT-4.0 Mini (the default for new builds) some use cases demand more conversational nuance, memory, or logical complexity than Mini-class models can reliably support.
This guide outlines the capabilities, trade-offs, and real-world applications of every model currently supported in Regal.
Whether you're optimizing for low-latency, prompt compliance, memory retention, or expressive output, each model behaves differently under load and in production call flows. We'll walk through how to align your model selection with your technical requirements and business objectives, and when it's worth testing or upgrading to a different LLM.
Your choice of LLM impacts both cost and performance, especially at scale.
Selecting the wrong model can result in degraded agent performance, whether through hallucinated outputs, broken function calls, or unnecessary latency. Conversely, a well-matched model can materially improve task resolution rates, reduce fallbacks, and expand the range of calls your agent can handle autonomously.
And then, of course, there’s the cost of each model.
The benefit of a platform like Regal is that it makes model experimentation low-risk and reversible. You can test different LLMs at your own risk, and use a variety of LLMs for agents across different call types.
In other words, you can find the right cost-to-performance ratio for any and every use case. The goal isn’t to use the cheapest or most powerful model by default, it’s to use the right one for the job.
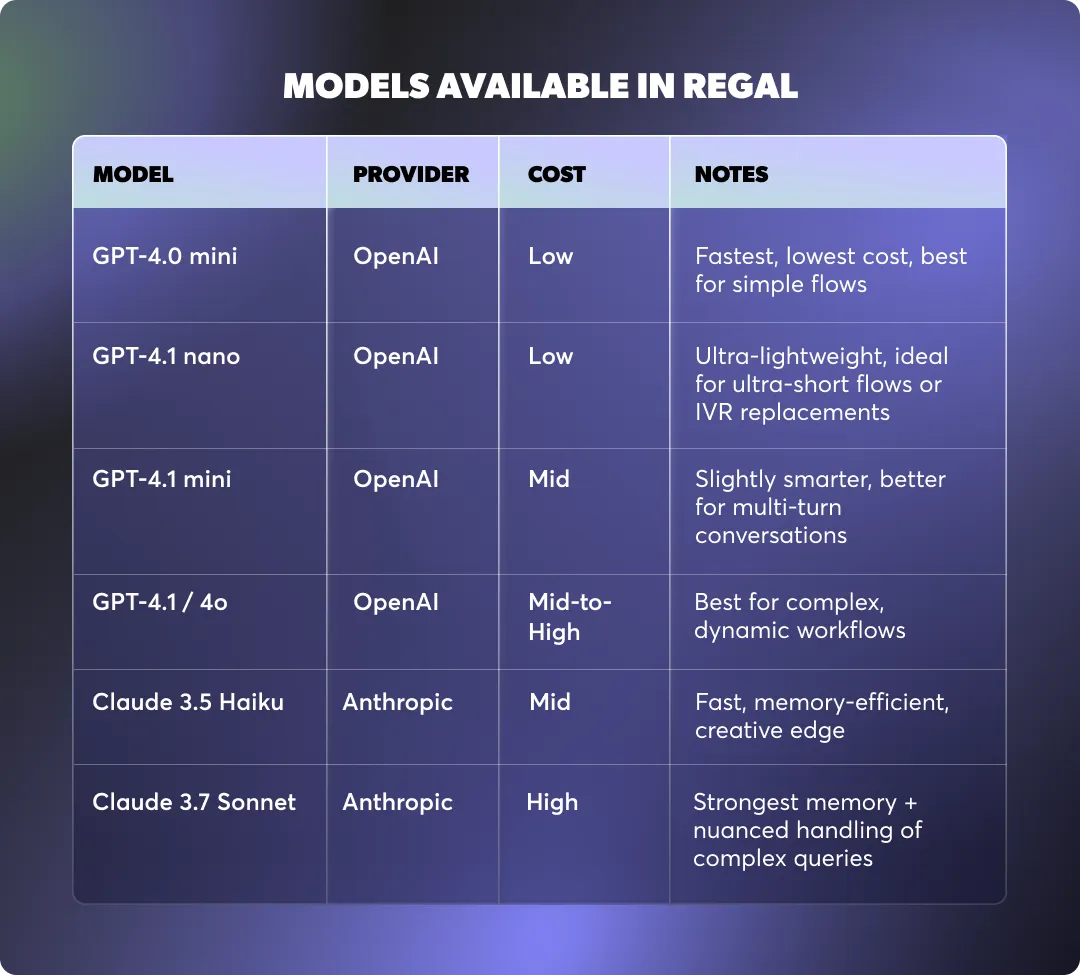
OpenAI models are the most widely used for Regal AI Agents because they strike the right balance between cost, speed, and conversational capability. They provide a good performance-to-cost ratio across common contact center workflows.
But not all OpenAI models behave the same.
Within the 4.x family, there are important differences in reasoning ability, conversational tone, and function-calling reliability.
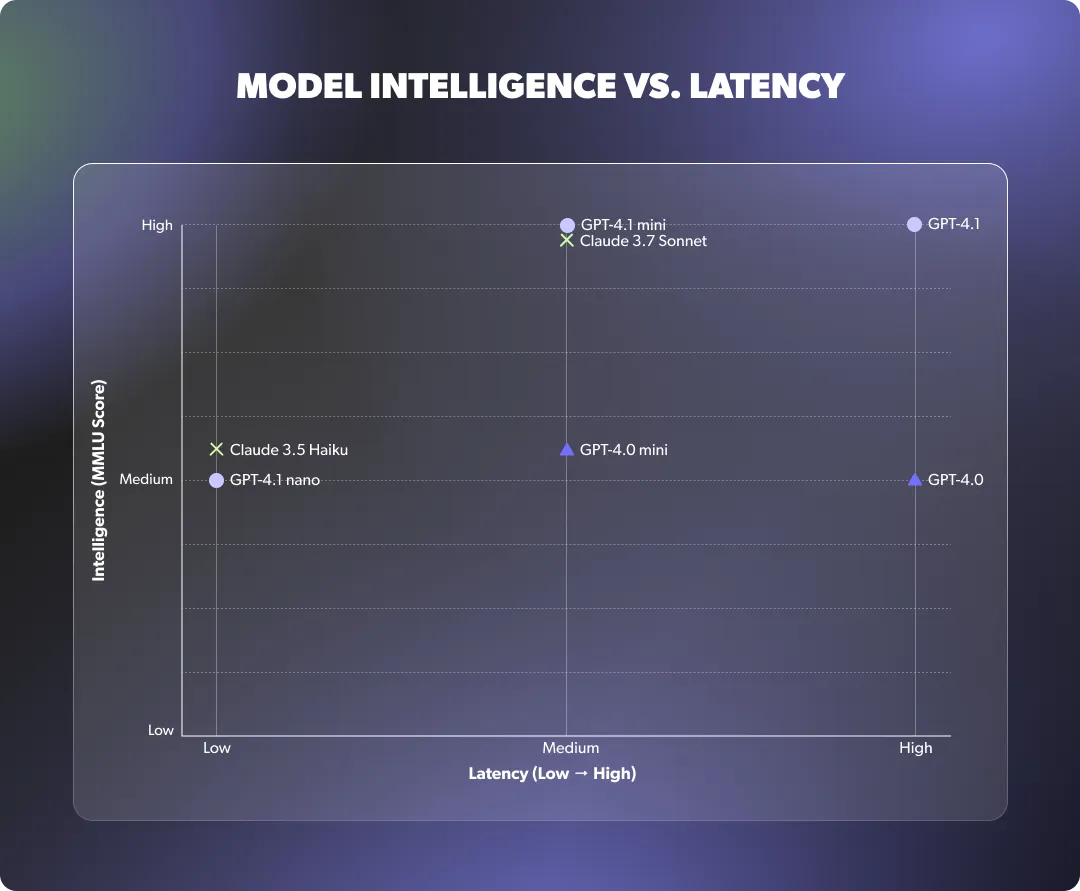
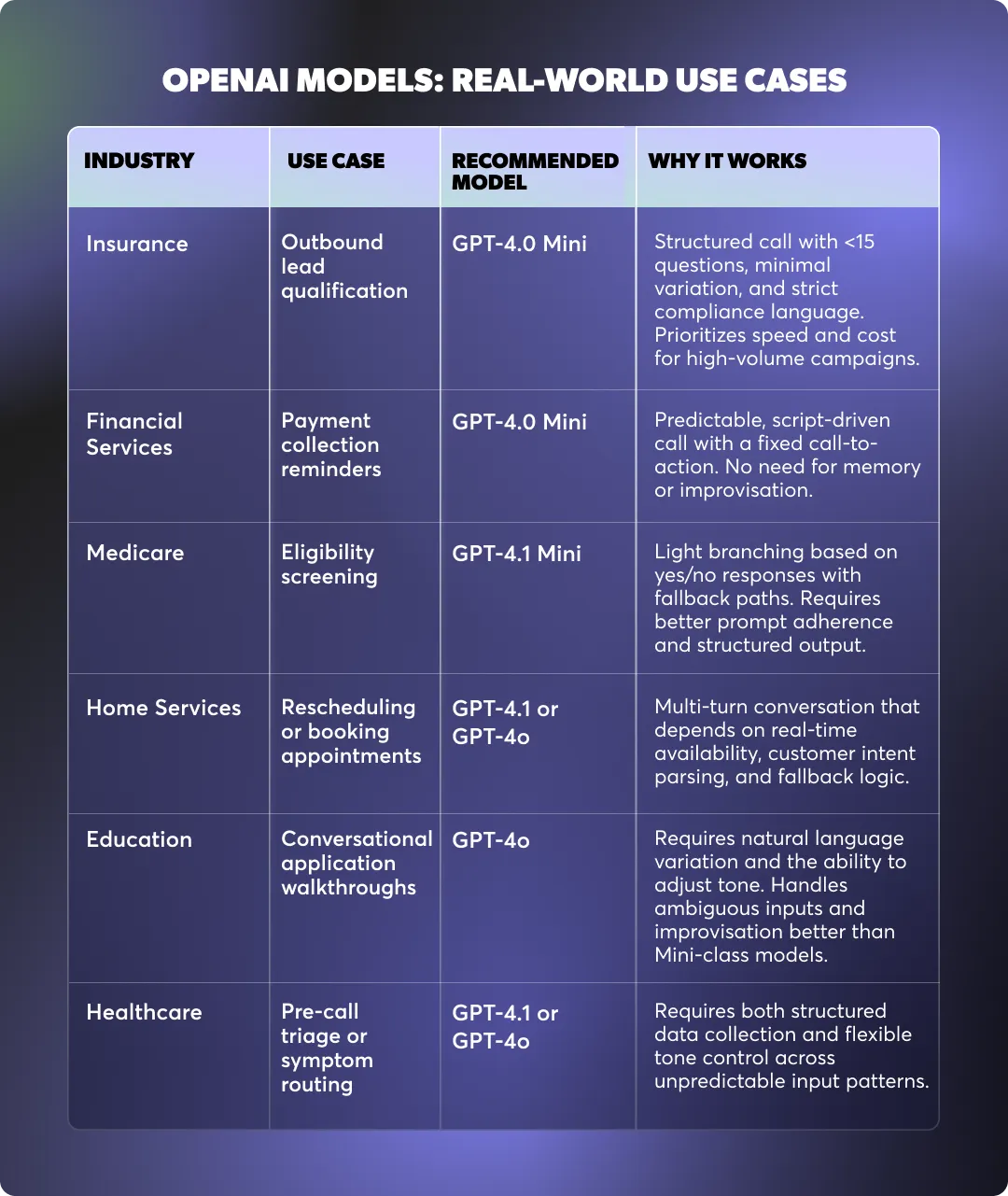
Below is a breakdown of when to use each OpenAI model supported in Regal, based on your AI Agent’s complexity and required behavior.
Best for: Fast, low-cost conversations that follow a structured and predictable script.
GPT-4.0 Mini is highly efficient for task types that require minimal reasoning and no memory retention. It performs best in tightly scoped flows where the contact’s responses are expected and the agent's behavior is well defined by the prompt.
GPT-4.0 Mini generally offers the most efficient performance for structured, predictable flows. It is the default model in Regal, with roughly 60% of all Voice AI Agents in the platform using it.
Use GPT-4.0 Mini when:
You’re running short, highly structured calls with limited branching—typically under 15 conversational steps—and where the agent is executing a predefined script with minimal variability.
Common examples include outbound lead confirmations, fixed-format qualification calls, and collections workflows that follow a rigid compliance sequence. It’s also suitable for contact scenarios where latency or cost are a key constraint and logic complexity is low.
Strengths:
Limitations:
Best for: Slightly more dynamic calls where turn-taking or light branching is required.
In terms of capability, this model sits between GPT-4o Mini and the more advanced models. It’s better at handling variation and light logic than 4o Mini, but still fast and cost-effective.
Use GPT-4.1 Mini when:
GPT-4.1 Mini is a good fit when your call flow includes conditional logic, follow-up paths, or rerouting behavior that requires the agent to make decisions based on earlier answers in the conversation.
It performs well in scenarios where branching logic is present but not deeply recursive, such as Medicare eligibility screening with yes/no responses, appointment rescheduling with fixed options, and multi-step qualification calls that require fallback paths.
Strengths:
Limitations:
Best for: Conversational experiences that prioritize tone, engagement, and expressive language.
GPT-4o offers a noticeable jump in conversational quality over mini models. It was designed to handle natural language more fluidly, with better control over prosody and variation in phrasing. It’s an ideal model for flows where the agent’s tone and ability to “improvise” make a measurable difference in customer outcomes.
Use GPT-4o when:
Your agent is expected to handle open-ended dialogue, shift tone based on customer sentiment, or build rapport through dynamic phrasing.
Use cases like inbound sales calls, support triage, and branded voice agents benefit from 4o’s natural dialogue capabilities. It also tolerates messier input more gracefully than GPT-4.1 Mini, making it more resilient to unpredictable customer behavior.
Strengths:
Limitations:
Best for: Complex, action-heavy flows that require precision, accuracy, and structured decisioning.
GPT-4.1 is Regal’s most reliable OpenAI model for deterministic task handling. It’s the preferred choice when your agent needs to call multiple custom actions, follow complex logic trees, or manage workflows with nested conditionals.
Its structured output is easier to control and test, especially in production environments where consistency matters.
Use GPT-4.1 when:
Your call involves chaining multiple actions together (i.e. a set of API calls to update a custom CRM), handling variable inputs across 10+ turns, or performing tasks that require mathematical reasoning or eligibility logic.
Common examples include detailed scheduling flows, custom quoting, and dynamic routing based on profile attributes. GPT-4.1 is also highly effective for prompt patterns that rely on precision formatting or strict logic gates.
Strengths:
Limitations:
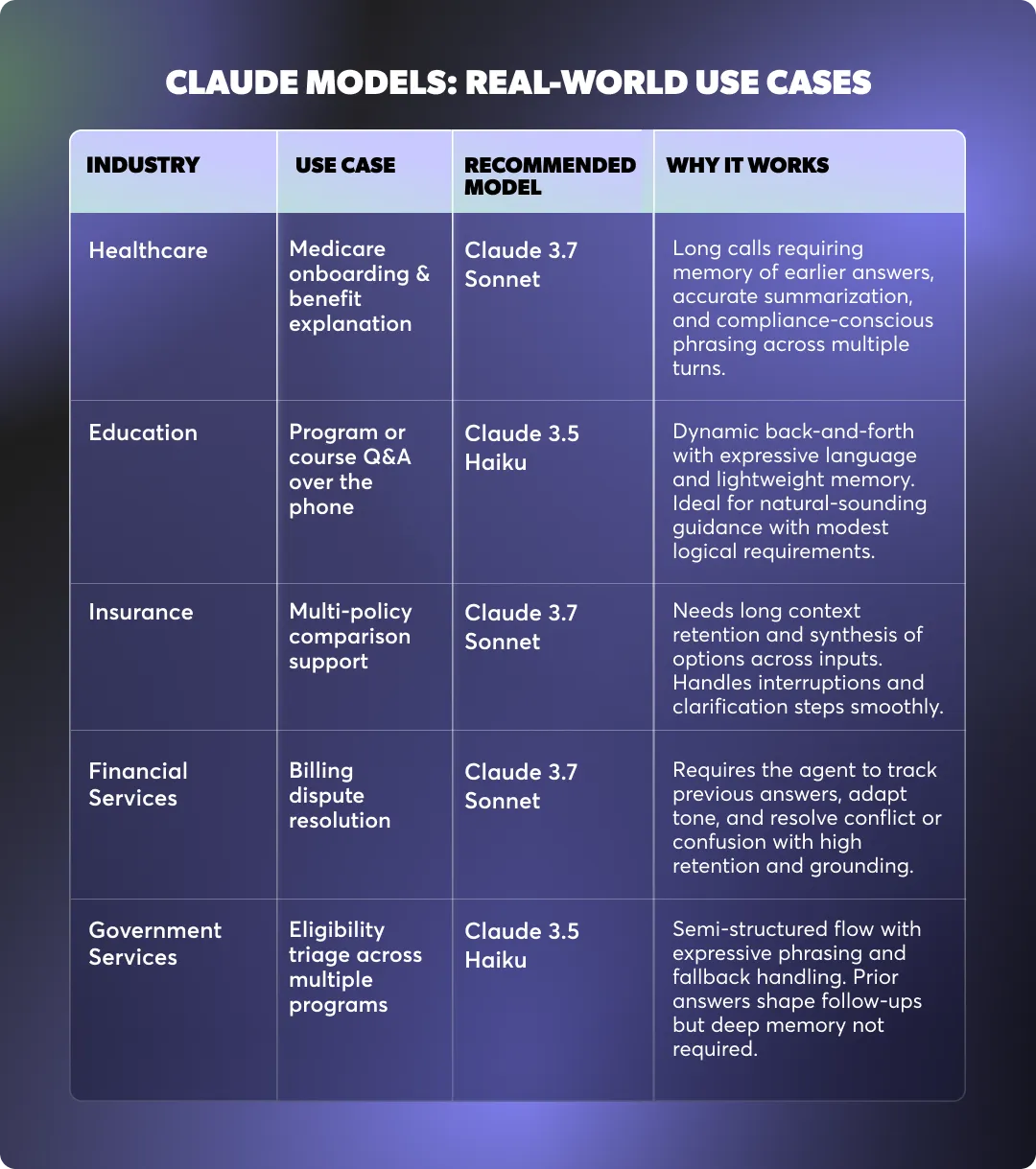
While most Regal agents start on OpenAI, there are real advantages to using Claude models, particularly in scenarios that demand strong memory, creative phrasing, or high resilience to edge cases.
Claude models, built by Anthropic, are known for their ability to reason over long contexts, stay grounded in prior conversation turns, and output language that feels polished and human, even in unpredictable flows.
Below is a breakdown of when and how to consider using Claude models in Regal.
Best for: Fast, expressive conversations with lightweight memory and stylistic polish.
Claude 3.5 Haiku performs well in scenarios that benefit from human-like phrasing and a bit of memory retention, but don’t require long context windows or complex decision trees.
Use Claude 3.5 Haiku when:
Your call is short to mid-length, with moderate personalization and moments where natural phrasing or variation improves the customer experience.
Examples include education or benefits onboarding calls, outbound application guidance, and light support flows that don’t involve decision trees or API-heavy logic. It can also be useful when the same agent is expected to interact across voice and SMS, thanks to its fluent multi-modal language generation.
Strengths:
Limitations:
Best for: Long, unpredictable conversations that require memory, nuance, and synthesis.
Claude 3.7 Sonnet excels in memory-intensive scenarios where earlier answers must be referenced later in the call. It’s the best choice for workflows that involve summarization, complex triage, or emotionally sensitive phrasing.
Use Claude 3.7 Sonnet when:
Your AI Agent is handling inbound support or onboarding calls that span multiple topics, require data retention across 20+ turns, or involve compliance-sensitive messaging.
It’s particularly strong in industries like healthcare, financial services, or insurance, where the agent must synthesize information and restate it accurately while maintaining control over tone and privacy requirements.
Sonnet also performs well in recovery flows, where fallback logic relies on tracking previous failures or attempted alternative paths.
Strengths:
Limitations:
Not every performance issue is a model issue. Before upgrading, focus on tuning the components around the LLM:
If you’ve already optimized your flow and the agent still fails to retain earlier answers across turns, struggles with vague input or off-script customer behavior, or outputs phrasing that feels robotic or unnatural, it’s time to test an upgraded model.
Always test new models in live call environments with production-level volume: Even small changes in model behavior can affect latency, cost, and agent containment. Use A/B testing to quantify improvements before making a full switch.
Model selection is not a one-time decision. As your AI Agent use cases evolve, from basic qualification to dynamic scheduling or multi-topic support, your LLM needs may shift accordingly.
Start with the model that fits your current complexity and budget. Optimize prompts, fallbacks, and workflows first. Then, if performance gaps remain, test higher-tier models that align with your requirements for memory, logic, or conversational quality.
Regal’s platform makes it easy to switch, compare, and iterate without rebuilding your agent from scratch. And we’ll work with you at every step.
Use that flexibility to your advantage, and choose the model that delivers the right balance of performance, predictability, and cost for your specific flow.
For model benchmarks and live testing guidance, see the Regal Developer Docs.


.webp)
With AI agents, every appointment gets a confirmation call. Each contact gets a chance to reschedule, and the confirmation rate goes to 100%, not because the AI is better at conversations than your agents, but because the AI never runs out of capacity.

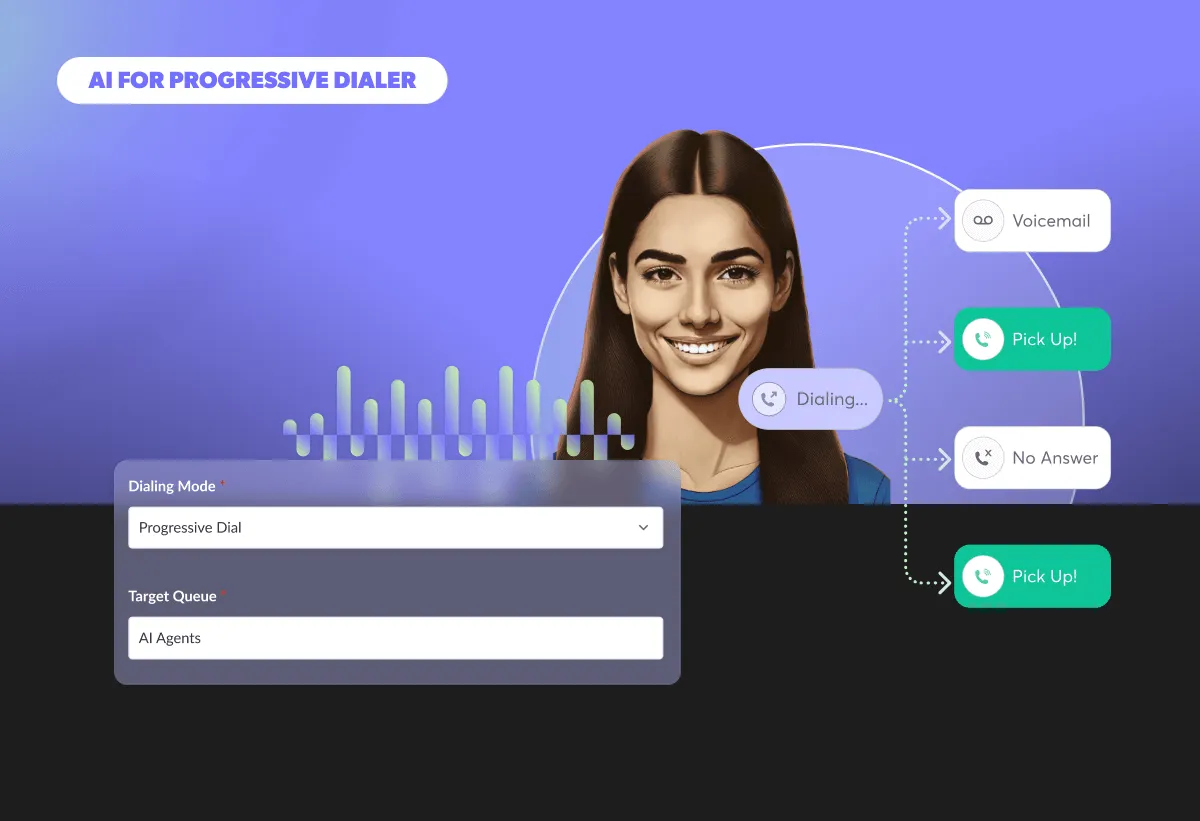
The fastest growing High Consideration brands have invested heavily in outbound call centers for sales and marketing. With the right technology, staffing and measurement, you too can build a high performing outbound call center to help hit your growth goals.
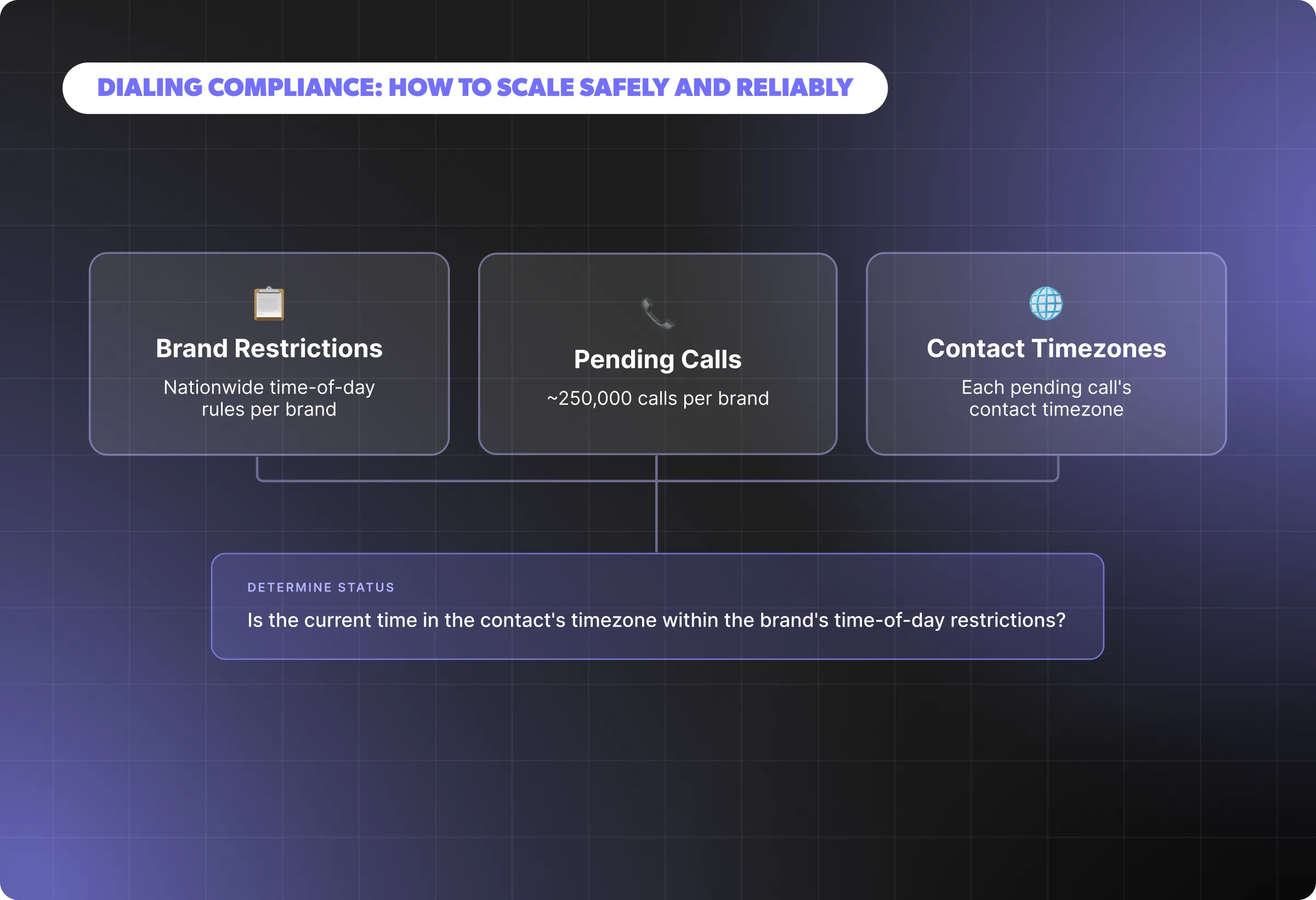
Behind a fragmented and ever-changing regulatory landscape is a simple goal: protecting people from unwanted or poorly timed outreach and giving them control over how they’re contacted. In practice, that responsibility translates into a set of checks that must be validated.

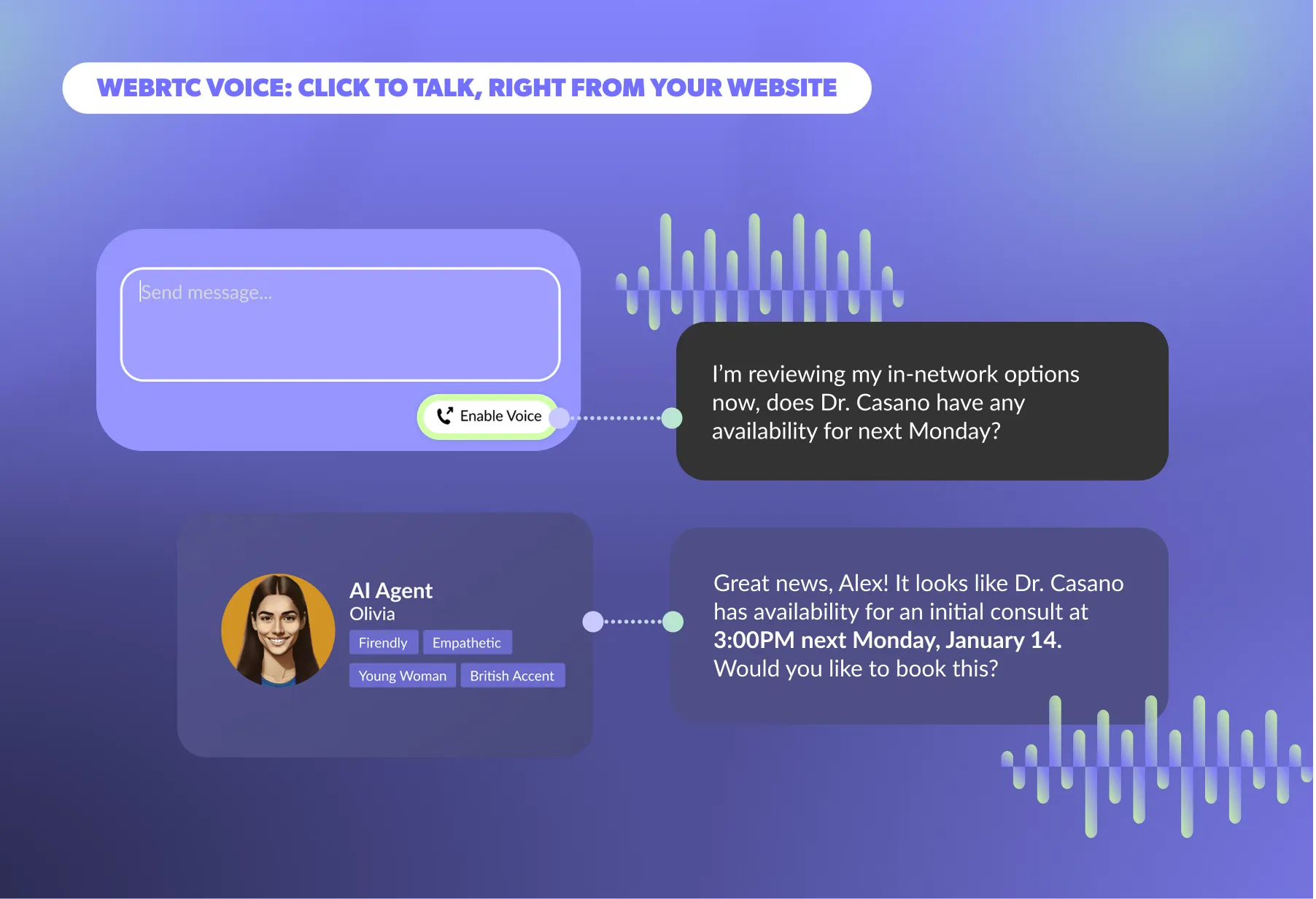
AI phone agents aren't just better phone trees. They are autonomous systems that can understand caller intent, retrieve relevant information from your CRM in real time, execute actions, handle objections and clarifications, and complete the conversation without human involvement.
.webp)
When prospects in healthcare and financial services hear "PII," they often imagine bulk data transfer: the idea that deploying an AI agent means copying a database somewhere. In most modern deployments, that's not what's happening.

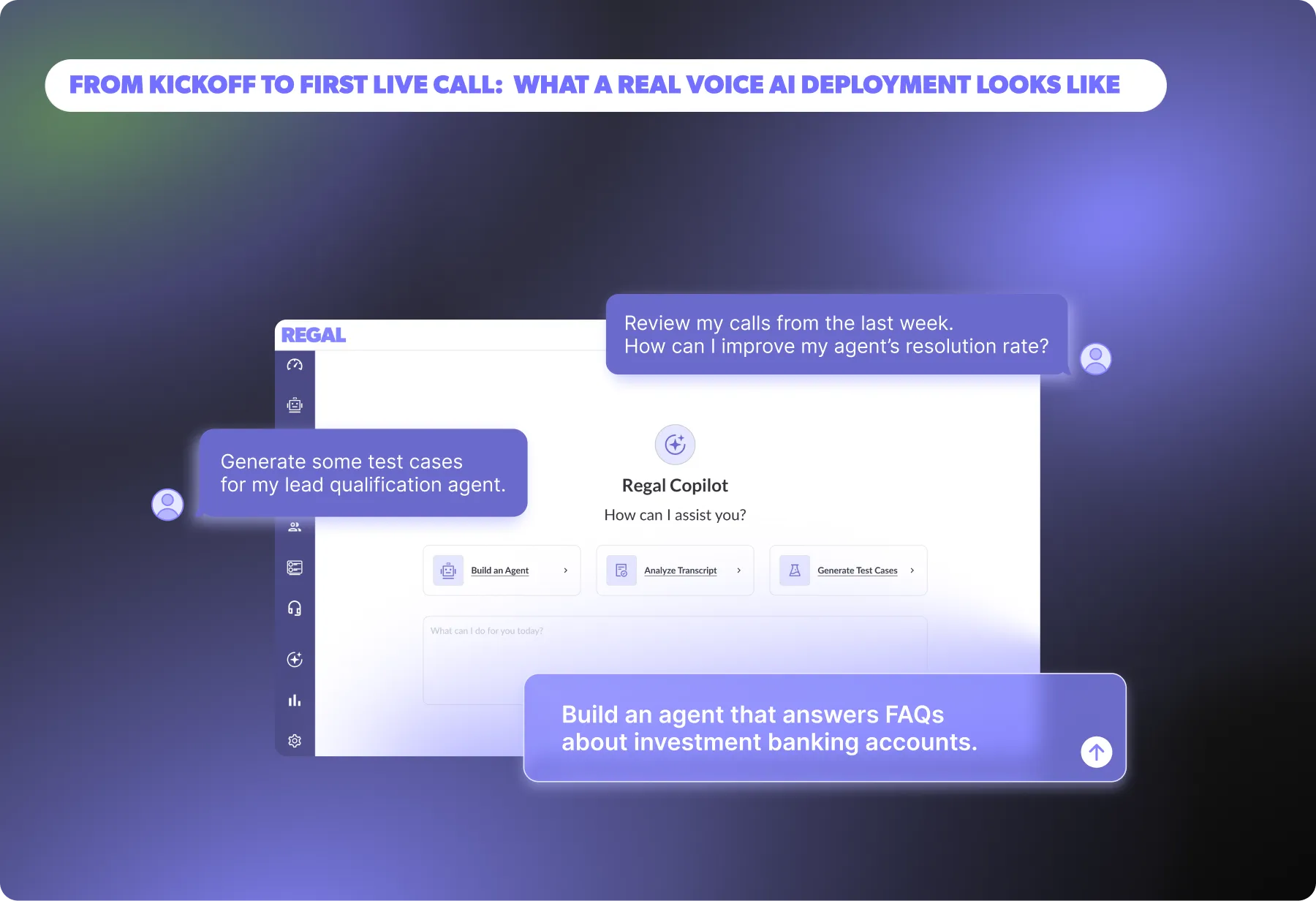
In March, we made it faster than ever to build, launch, and continuously improve AI agents with Copilot, Regal's AI agent for building AI agents. Together, these updates lessen the time needed to launch and maintain agents, so you can focus on understanding your customers, unlocking new use cases, and driving faster business outcomes.
.webp)
AI agent performance depends on how well it aligns with real customer language, not just fluency. Regal Improve helps teams identify gaps and improve outcomes by analyzing real conversations and surfacing high-impact opportunities
.webp)
In this fireside chat, Regal Co-Founder & CEO Alex Levin sits down with Kin Insurance’s Austin Ewell and a360inc’s Henry Davidson to share how their organizations are using AI agents to transform outreach, customer experience, and operational efficiency. They discuss real-world deployments—from qualification and human agent handoffs to complex negotiation workflows—break down the results, and offer practical guidance for leaders adopting AI agents at scale.
.webp)
Learn about the difference between single-state and multi-state AI agents, and how each impacts speed, scale, and reliability. Discover when simplicity is enough and when enterprise workflows demand structured orchestration, so you can choose the right design for your use case.
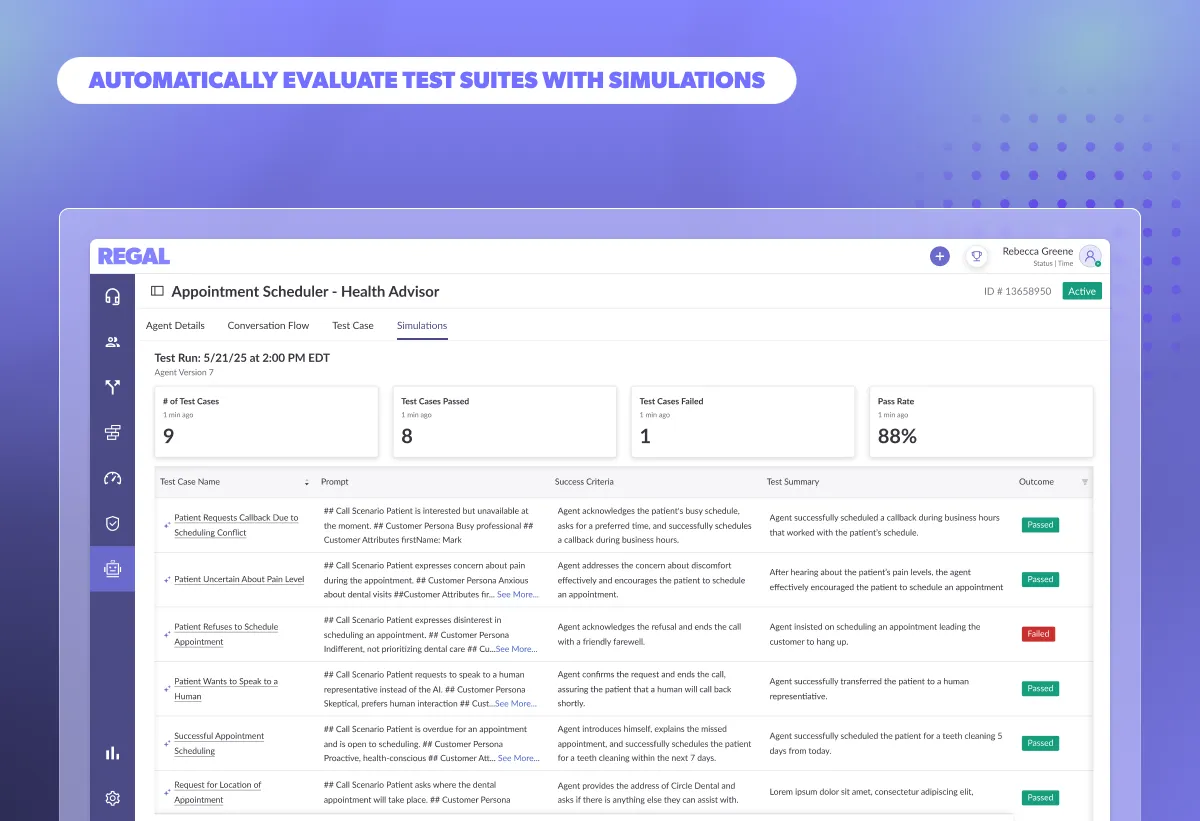
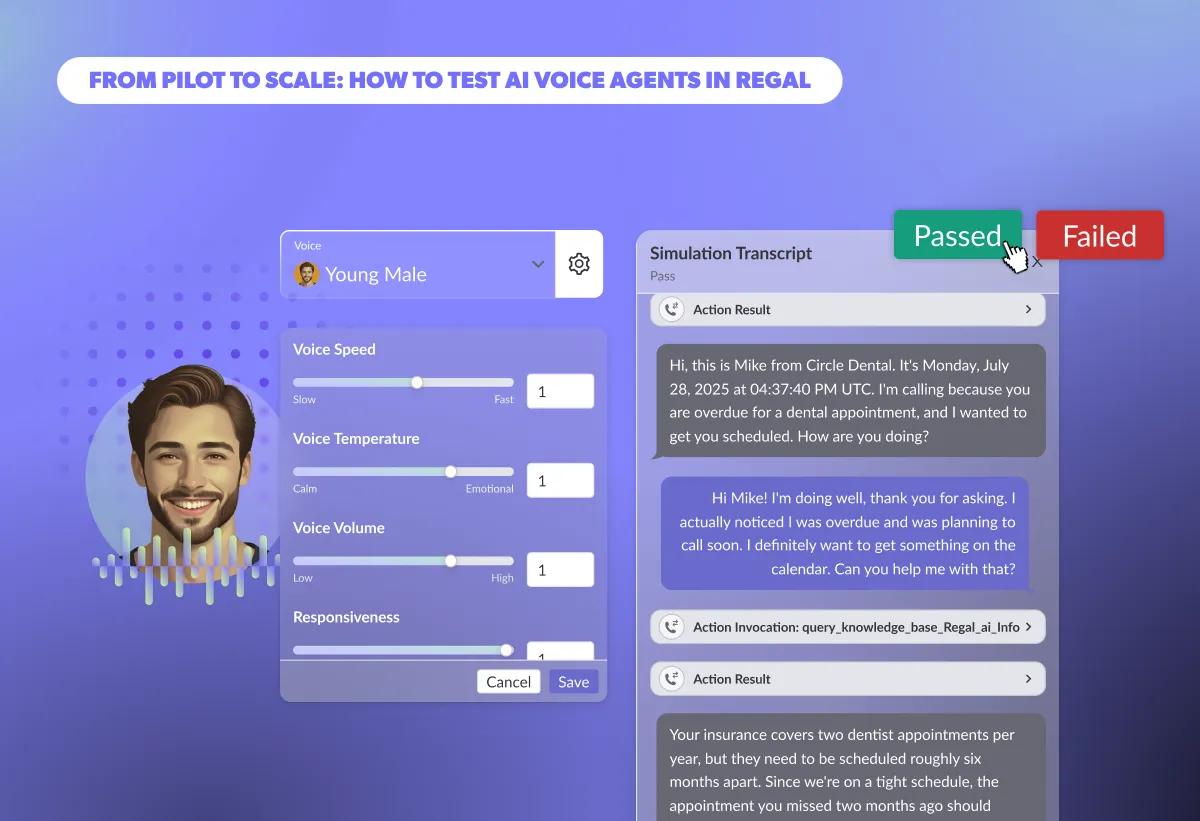
Discover how you can use Simulations to evaluate scenario-specific conversational flows that pinpoint AI Agent failures before launch. Speed up regression testing, validate prompts, knowledge bases, and custom actions at scale, and deploy reliable AI Agents with confidence.
%20(1).webp)
Apple’s iOS 26 introduces new call-screening controls that will reshape outbound performance. This guide explains what’s changing, how adoption may impact enterprise contact centers, and the proactive steps leaders can take now to protect answer rates and customer trust.
Learn how to maintain a clean, reliable RAG system for AI Agents. Discover best practices for structuring source docs, chunking content, titling for retrieval, avoiding redundancy, and keeping knowledge bases fresh to ensure accurate, scalable performance.
.webp)
This article outlines the core characteristics that influence how voice AI is perceived on live calls. From mechanical traits like speed and volume, to more emotional and conversational behaviors, we’re going to look at what those characteristics mean, why they matter, and how they impact your bottom line.
.webp)
Learn how to configure your AI Voice Agent for real performance. This guide covers the most important voice settings in Regal, what ranges top brands use in production, and how adjusting speed, tone, and responsiveness impact cost, containment, and overall customer experience.

AI Agents for Education are transforming student engagement—boosting enrollment, improving retention, and making support more human. Discover 8 game-changing use cases that free up your staff while delivering better student outcomes.

Regal is officially one of Forbes America’s Best Startup Employers 2025, ranking #164 out of 500. This recognition is a testament to our incredible team, our innovative work culture, and our unwavering commitment to advancing AI technology.

AI in education is helping to streamline admissions, automate student engagement, and enhance higher ed outreach. Discover key education technology trends to boost enrollment and learn why automated student engagement tools are the future.
.webp)
When it comes to comparing AI Agents vs. AI Assistants, Siri & Alexa handle simple tasks, but Gen AI Voice Agents—like Regal’s AI Phone Agent—drive real business impact with human-like conversations, automation, and seamless integration.

As AI technology continues to evolve, the use cases for AI Voice Agents in contact centers will only increase. By answering these six key questions, you can identify where AI agents fit best today in your contact center and plan for future integrations.

Consumer businesses are implementing AI-enabled customer experiences without any change in behavior on the part of consumers, which is leading AI to become common with more speed than past transitions like the internet and the smartphone. And it means that the next step in AI will not come from the LLM providers. The next big step forward in AI rests in the hands of consumer businesses.

Explore Eric Hauser's remarkable career journey from GovTech to healthcare disruption at Cadence, highlighting the transformative power of innovation, collaboration, with a special focus on the pivotal role of Regal in driving patient engagement and outcomes.

Discover how Regal.io's AI-powered personalized outreach solutions are revolutionizing outbound sales and customer experience across industries like healthcare, finance, and insurance in our latest eBook, "Modernizing Outbound Contact Centers: How to Treat Millions of Customers like One in a Million."
Ready to see Regal in action?
Book a personalized demo.




.avif)
.webp)


.webp)
.webp)
.webp)

.webp)
.webp)
.webp)

.avif)


.webp)


.webp)


.webp)
.webp)

.webp)


%20(1).webp)
.webp)
%20(1).webp)
.png)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)
%20(1).webp)
%20(1).webp)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)

.webp)


%202.webp)


.webp)
.webp)
.webp)
.webp)











.avif)






