
SEPTEMBER 2023 RELEASES
September 2023 Releases
On a phone call, your brand has less than a second to make a good first impression. If an AI agent hesitates before its opening response, callers notice, and many hang up. That pause can feel awkward, undermining trust in the brand, and directly affects whether the conversation continues.
This is what makes voice AI fundamentally different from other ways people interact with language models today. When you're using ChatGPT or any chat-based assistant, a slightly slow first response is a minor annoyance, even an expectation. On a phone call, the stakes are higher because callers are accustomed to hearing a human on the other side of the line.
Contact center operators track call abandonment rates closely for exactly this reason: the first few seconds of a call determine whether the rest of it happens. That pause before an AI agent speaks is one of the most detectable signals that you're not talking to a human. In a cascaded voice AI architecture (where a separate LLM and text-to-speech provider each take their turn), that pause has a specific name: time to first token (TTFT).
TTFT is how long it takes the language model to begin generating a response after the caller finishes speaking. It's the biggest driver of perceived latency in a voice AI system. And over the past several weeks, it's where we've been focusing our engineering work.
The result: end-to-end response latency had a 26% improvement in roughly three weeks. This blog will cover what goes on behind each AI agent call, and the experiments we ran to improve latency.
Every time your AI agent responds, it sends a request to the LLM. That request includes the full system prompt: all the instructions about how the agent should behave, what tools it has access to, and how to handle different scenarios. On a long call, that prompt gets submitted and re-processed on every single turn.
Here’s a look at what happens behind every AI agent call:
.webp)
That processing is not free. The more tokens the model has to read before it can start generating, the longer your callers wait.
Prompt caching addresses this directly. The LLM caches its internal representation of the prompt so it doesn't have to re-read and re-process those tokens from scratch on subsequent turns. When the cache is loaded, the model skips straight to generating a response.
Within a single call, this is straightforward: after the first turn, the system prompt hasn't changed, so the cache stays valid and every subsequent turn benefits. The harder problem is caching across calls: keeping that saved work available when the next call comes in on the same agent.
OpenAI's caching works on a prefix-match basis. When a request comes in, the model hashes the initial portion of the prompt and routes it to a machine that may already have that prefix cached. If the prefix matches, it picks up where it left off. If it doesn't, it starts from scratch.
.webp)
The implication: the stable part of your prompt needs to come first. The system instructions, tool definitions, response format: anything that doesn't change call to call should sit at the top of the prompt so the prefix is consistent and cacheable across every call to that agent.
We've been doing the work to ensure our architecture takes full advantage of this. The goal is to maximize the percentage of input tokens that are cached on any given turn. The more of the prompt the model can skip re-reading, the faster your TTFT.
Here's where things get counterintuitive.
Even when a prompt is well-structured, a single variable or character in the wrong place can invalidate the cache on every single call. If your system prompt starts with call-specific content like "You are calling [First Name], a [Lead Type] customer from [Salesforce field]," then every call looks different to the model. The prefix never matches, and the cache never hits. You're paying full processing cost every time.
This is exactly the pattern we found: call-specific details (first name, lead type, Salesforce attributes) were being rendered at the top of the prompt, invalidating the cache for new calls.
.webp)
The fix was moving that dynamic content to the end of the context, after the stable system instructions. That way, the large, consistent portion of the prompt stays cacheable across calls, and only the small, variable portion needs fresh processing.
When the prompt is cacheable across calls, this creates a significant decrease to TTFT (time to first token), which in turn shortens the pause before an AI agent speaks. We found that this was a small structural change with a significant latency payoff.
Before measuring improvement, we needed to understand where the opportunity was. The chart below breaks down the portion of cached requests by input size:
.webp)
For extra-large inputs (over 10k tokens), 78.6% of requests already achieve high cache hit rates. The medium-to-large range (2k to 10k tokens) is where the highest volume of requests sits, and where fixing the prefix structure would have the broadest impact across the platform.
That's what we went after. The results show up clearly in cache hit rates on first turns. A first turn is the agent's opening response at the start of a new call. Unlike mid-call turns, which can reuse the cache built up within that conversation, a first turn has to rely on a cache carried over from a prior call. If that cache has expired, the model processes the full prompt from scratch. That's why first turns are the hardest to cache consistently, and the most important ones to get right.
That progression tracks directly with the E2E latency improvement: from the week of April 13 to early May, there was a 26% reduction in latency.
The work we're doing on latency doesn't stop here; we're still optimizing the percentage of tokens that are cached per request (not just whether any tokens are cached), which is the metric that drives the biggest TTFT gains. Our target is consistently above 90% of input tokens cached, given that the only thing changing turn-to-turn should be the new user utterance, a small fraction of the overall context.
Prompt caching is one lever of improving latency, but it's not the only one.
We're actively testing faster voice models, smarter handling of tool calls so the agent says something natural while it looks up information rather than going silent, and additional model options with lower baseline latency. We're also exploring architectural changes that let us start LLM processing before the end-of-utterance detection fully completes, shaving off latency from both sides of the equation simultaneously.
Ready to see Regal's voice AI in action? Schedule a demo.
TTFT is the time between when a caller finishes speaking and when the language model begins generating a response. In a cascaded voice AI architecture that uses a separate LLM and TTS provider, TTFT is the primary driver of the pause callers hear before the AI agent speaks.
Prompt caching lets the LLM save its internal representation of your system prompt so it doesn't have to re-read and re-process those tokens on every turn. When a request comes in with a matching prompt prefix, the model skips the processing it already did and jumps straight to generating a response, reducing TTFT on every cached turn.
LLM caching works by matching the initial portion of a prompt (the prefix) against previously processed requests. If contact-specific details like a caller's name or Salesforce data appear early in the prompt, every call has a unique prefix, so no cached version ever matches. Moving that dynamic data to the end of the context preserves the cacheable prefix and allows caching to work across calls.
Results vary by architecture and prompt structure, but Regal has seen a 26% end-to-end latency drop by optimizing prompt structure for caching. The biggest gains come from maximizing the percentage of input tokens that are cached, not just whether any caching is occurring.
End-of-utterance (EOU) detection adds latency before the LLM request even fires. Text-to-speech (TTS) generation adds latency after the LLM responds. Tool calls (where the agent looks up information mid-conversation) can introduce silent pauses if not handled well. Reducing latency in production requires optimizing all of these components, not just model speed.


.webp)
With AI agents, every appointment gets a confirmation call. Each contact gets a chance to reschedule, and the confirmation rate goes to 100%, not because the AI is better at conversations than your agents, but because the AI never runs out of capacity.

The fastest growing High Consideration brands have invested heavily in outbound call centers for sales and marketing. With the right technology, staffing and measurement, you too can build a high performing outbound call center to help hit your growth goals.
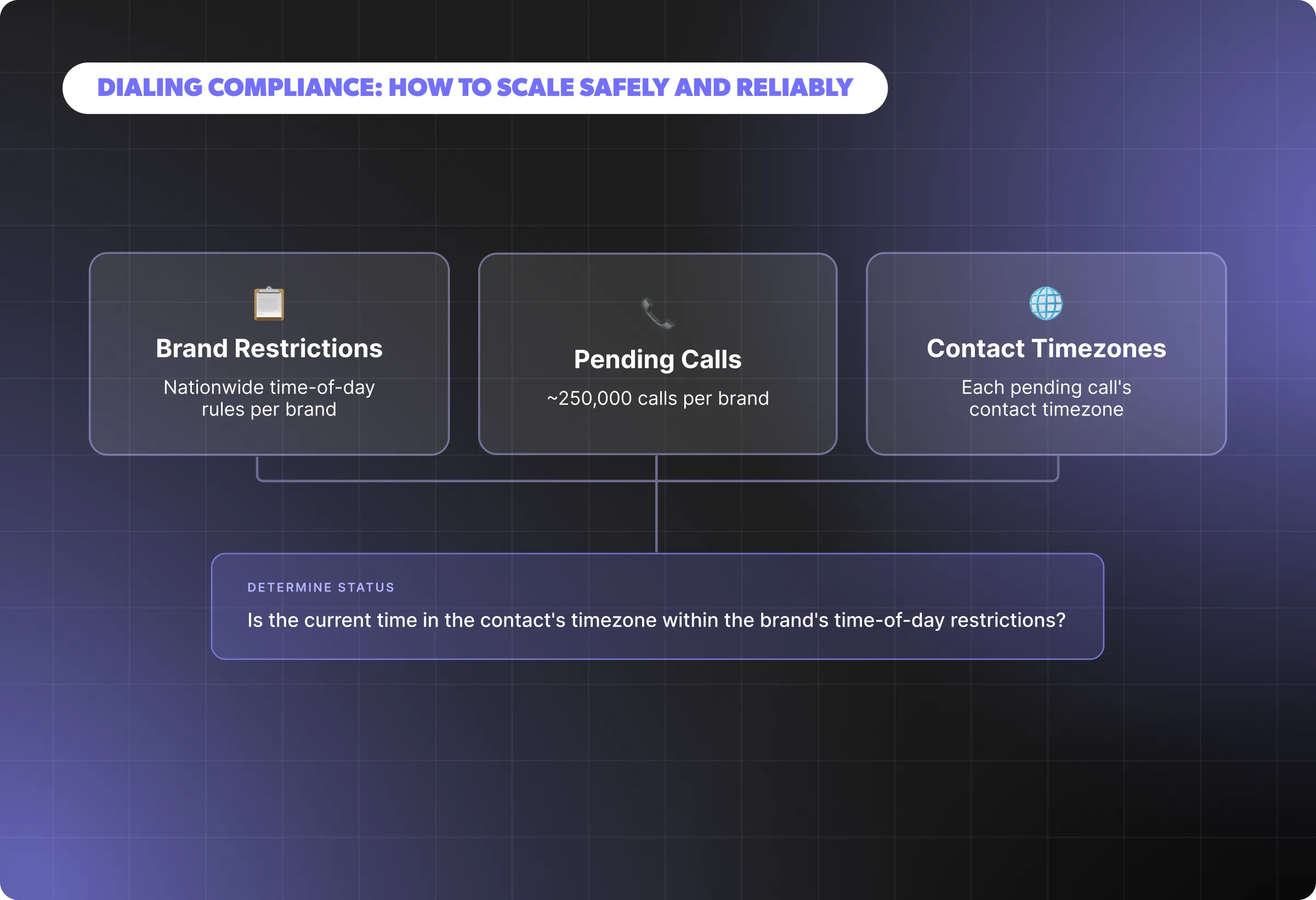
Behind a fragmented and ever-changing regulatory landscape is a simple goal: protecting people from unwanted or poorly timed outreach and giving them control over how they’re contacted. In practice, that responsibility translates into a set of checks that must be validated.

AI phone agents aren't just better phone trees. They are autonomous systems that can understand caller intent, retrieve relevant information from your CRM in real time, execute actions, handle objections and clarifications, and complete the conversation without human involvement.
.webp)
When prospects in healthcare and financial services hear "PII," they often imagine bulk data transfer: the idea that deploying an AI agent means copying a database somewhere. In most modern deployments, that's not what's happening.

In March, we made it faster than ever to build, launch, and continuously improve AI agents with Copilot, Regal's AI agent for building AI agents. Together, these updates lessen the time needed to launch and maintain agents, so you can focus on understanding your customers, unlocking new use cases, and driving faster business outcomes.
.webp)
AI agent performance depends on how well it aligns with real customer language, not just fluency. Regal Improve helps teams identify gaps and improve outcomes by analyzing real conversations and surfacing high-impact opportunities
.webp)
In this fireside chat, Regal Co-Founder & CEO Alex Levin sits down with Kin Insurance’s Austin Ewell and a360inc’s Henry Davidson to share how their organizations are using AI agents to transform outreach, customer experience, and operational efficiency. They discuss real-world deployments—from qualification and human agent handoffs to complex negotiation workflows—break down the results, and offer practical guidance for leaders adopting AI agents at scale.
.webp)
Learn about the difference between single-state and multi-state AI agents, and how each impacts speed, scale, and reliability. Discover when simplicity is enough and when enterprise workflows demand structured orchestration, so you can choose the right design for your use case.
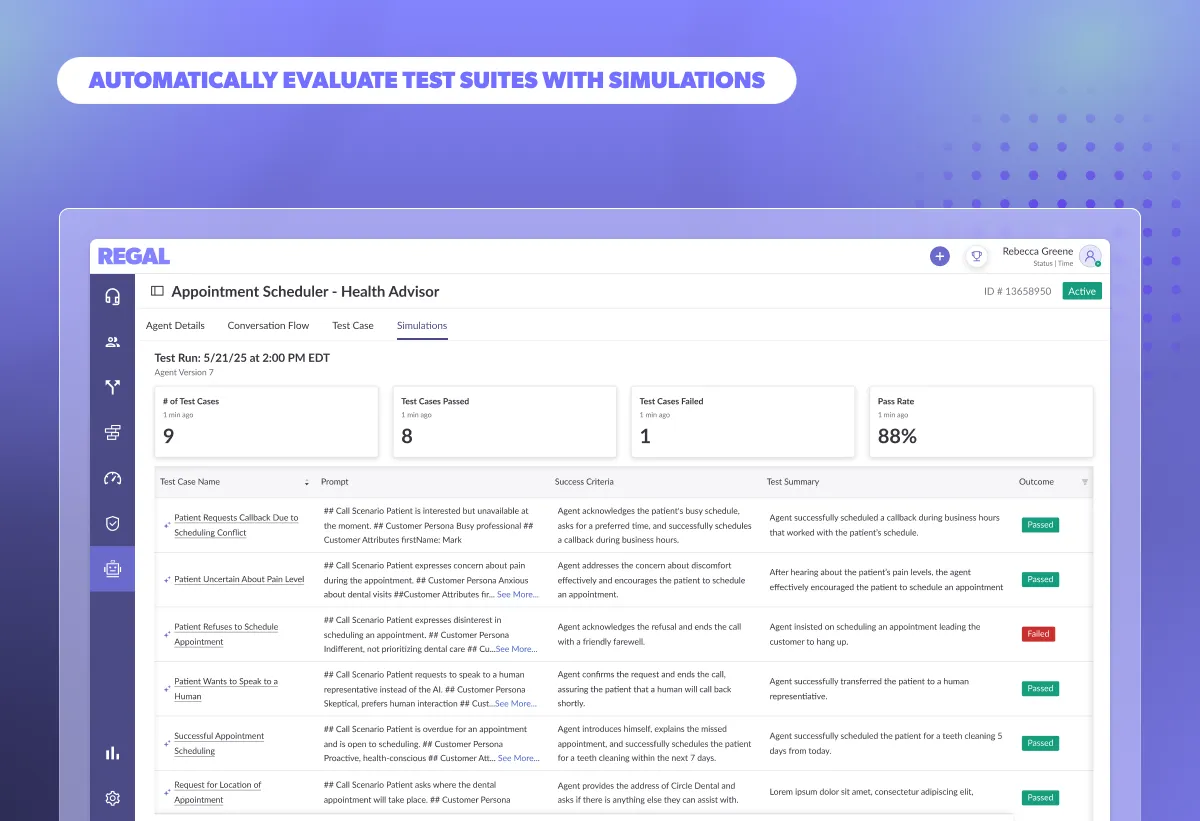
Discover how you can use Simulations to evaluate scenario-specific conversational flows that pinpoint AI Agent failures before launch. Speed up regression testing, validate prompts, knowledge bases, and custom actions at scale, and deploy reliable AI Agents with confidence.
%20(1).webp)
Apple’s iOS 26 introduces new call-screening controls that will reshape outbound performance. This guide explains what’s changing, how adoption may impact enterprise contact centers, and the proactive steps leaders can take now to protect answer rates and customer trust.
Learn how to maintain a clean, reliable RAG system for AI Agents. Discover best practices for structuring source docs, chunking content, titling for retrieval, avoiding redundancy, and keeping knowledge bases fresh to ensure accurate, scalable performance.
.webp)
This article outlines the core characteristics that influence how voice AI is perceived on live calls. From mechanical traits like speed and volume, to more emotional and conversational behaviors, we’re going to look at what those characteristics mean, why they matter, and how they impact your bottom line.
.webp)
Learn how to configure your AI Voice Agent for real performance. This guide covers the most important voice settings in Regal, what ranges top brands use in production, and how adjusting speed, tone, and responsiveness impact cost, containment, and overall customer experience.

AI Agents for Education are transforming student engagement—boosting enrollment, improving retention, and making support more human. Discover 8 game-changing use cases that free up your staff while delivering better student outcomes.

Regal is officially one of Forbes America’s Best Startup Employers 2025, ranking #164 out of 500. This recognition is a testament to our incredible team, our innovative work culture, and our unwavering commitment to advancing AI technology.

AI in education is helping to streamline admissions, automate student engagement, and enhance higher ed outreach. Discover key education technology trends to boost enrollment and learn why automated student engagement tools are the future.
.webp)
When it comes to comparing AI Agents vs. AI Assistants, Siri & Alexa handle simple tasks, but Gen AI Voice Agents—like Regal’s AI Phone Agent—drive real business impact with human-like conversations, automation, and seamless integration.

As AI technology continues to evolve, the use cases for AI Voice Agents in contact centers will only increase. By answering these six key questions, you can identify where AI agents fit best today in your contact center and plan for future integrations.

Consumer businesses are implementing AI-enabled customer experiences without any change in behavior on the part of consumers, which is leading AI to become common with more speed than past transitions like the internet and the smartphone. And it means that the next step in AI will not come from the LLM providers. The next big step forward in AI rests in the hands of consumer businesses.

Explore Eric Hauser's remarkable career journey from GovTech to healthcare disruption at Cadence, highlighting the transformative power of innovation, collaboration, with a special focus on the pivotal role of Regal in driving patient engagement and outcomes.

Discover how Regal.io's AI-powered personalized outreach solutions are revolutionizing outbound sales and customer experience across industries like healthcare, finance, and insurance in our latest eBook, "Modernizing Outbound Contact Centers: How to Treat Millions of Customers like One in a Million."
.jpeg)
Combining collaboration functionality into CCaaS workflow tools invites more cross-functional users from a company to participate in designing the end-customer experience, leading to better omni-channel orchestration and customer outcomes. Learn more about Regal's collaboration features.
Ready to see Regal in action?
Book a personalized demo.




.avif)


.webp)
.webp)
.webp)

.webp)
.webp)
.webp)

.avif)


.webp)


.webp)


.webp)
.webp)

.webp)


%20(1).webp)
.webp)
%20(1).webp)
.png)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)
%20(1).webp)
%20(1).webp)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)

.webp)


%202.webp)


.webp)
.webp)
.webp)
.webp)











.avif)






