
SEPTEMBER 2023 RELEASES
September 2023 Releases
The conversation around AI agent deployment usually stalls somewhere around week three. Legal gets involved. IT security flags a risk. Someone from compliance asks what happens to the call data. The procurement process that was moving forward suddenly isn't.
After powering 400M calls, we know that regulated industries run the most complex contact center environments in existence: multiple systems of record, data governance requirements that vary by state, and compliance obligations that touch every step of the customer interaction. That complexity is what makes the PII question feel so high-stakes. It brings in every stakeholder at once.
Most of the time, this delay isn't the result of a real blocker. It's the result of a misframed question. "Is it safe to send patient data to an AI platform?" is the wrong question. The right one is: "What data does the AI agent actually need to do its job, and what happens to everything else?" These are very different questions. And the answer to the second determines whether your deployment lands next quarter or gets stuck in a procurement spiral for twelve months.
The AI agents deployed across healthcare, insurance, and financial services don't need access to full patient records to verify identity, confirm an appointment, or collect a past-due payment. They need a subset of data: the fields relevant to the specific task at hand. With the support of our Forward Deployed Engineers, you can design that data retrieval precisely in every agentic workflow
Here's what that looks like in practice, and why getting it right isn't nearly as hard as most procurement teams assume.
The fear behind most data security objections is reasonable: an AI agent that can see everything a human agent can see carries the same risk profile as any other privileged access point. But that's a design choice, not a technical constraint.
.webp)
Regal AI Agents use Custom Actions (API calls made mid-conversation) to retrieve only the data relevant to the current step in the conversation. An agent handling Medicare enrollment confirmation, for example, doesn't start the call with the full member record preloaded. It retrieves the coverage status when that question comes up, and nothing else. What the agent sees is scoped to what the agent needs.
This selective sync model is exactly what companies in regulated industries should be designing for from the start. Treat data retrieval as an architecture decision, not an IT security afterthought.
When prospects in healthcare and financial services hear "PII," they often imagine bulk data transfer: the idea that deploying an AI agent means copying a database somewhere. In most modern deployments, that's not what's happening.
There are two common integration patterns, and the security implications are very different.
Pattern 1: Real-time retrieval via Custom Actions. The AI agent calls your system of record mid-conversation to retrieve a specific field (e.g., "Is this patient's appointment confirmed?"). No data is persisted on the agent platform beyond what's needed for the call. This is the lower-risk design pattern for PHI and PII.
Pattern 2: Contact field sync. A subset of contact fields (name, phone number, account ID, custom flags) is synced from your CRM to Regal to power Journey Builder and outbound campaigns. You control which fields sync. Regal's integrations with Salesforce, HubSpot, and 40+ other platforms support field-level sync configuration.
The question to ask in your security review isn't "does data touch the platform?" It's "which data, controlled by whom, for what duration?"
One of the trickiest compliance moments in an AI agent call is identity verification. It's the step where regulated industries most often want to fall back to humans, and where good architecture proves its value.
Regal's Authenticate Contact Action handles real-time identity verification during calls by checking the caller's responses against known contact attributes already stored in Regal. The match is evaluated on a configurable threshold (strong match or exact match) before the agent proceeds to any protected action.
.webp)
What this means in practice: your AI agent can verify a caller's identity against their account number, date of birth, or other attributes without retrieving their full patient or policyholder record at the start of the call. The verification step is isolated, so protected data stays protected until access is earned.
For regulated industries, this pattern satisfies the core compliance requirement: prove who you're talking to before sharing anything sensitive, while maintaining a clean data separation between verification and access.
For healthcare deployments in particular, the pattern has proven durable.
Read more about our work with eHealth to see how this works at scale in a compliance-heavy enrollment context.

In practice, the teams that move fastest through security review come in with a completed data mapping exercise: a list of every task the AI agent will handle, paired with the minimum data fields each task requires. That document transforms the security conversation from "is this safe?" (unanswerable in the abstract) to "here are exactly the 7 fields the agent will retrieve, here's when, and here's how they're scoped."
It's worth doing this exercise before you get to procurement. The teams that get stuck are the ones treating data architecture as an IT question to answer after the AI strategy is decided. The ones that move fast treat them as the same question.
For insurance deployments, the same principle applies. At Regal, we've worked with insurance carriers to move from evaluation to production by resolving the data architecture questions upfront, not in parallel with legal review.
The PII and PHI question, properly scoped, is a 2 to 4 week architecture conversation, not a 6-month procurement delay. The organizations that move fastest treat data security as a design input, not a barrier
If you're in a regulated industry evaluating AI agents now, the highest-leverage thing you can do is bring your IT security team into the architecture conversation early: not to approve the deployment, but to help design the data flow with our Forward Deployed Engineers. Their early input makes the later approval significantly faster.
Want to see how other healthcare, insurance, and financial services companies have structured their AI agent data integrations? Let's talk.
Regal AI Agents can operate in two modes: real-time API retrieval (data is called mid-conversation and not persisted) and contact field sync (where you control exactly which fields from your CRM are synced to Regal). Most healthcare and insurance deployments use a combination of both, with PHI-sensitive fields retrieved in real time rather than stored. Specific data retention and security architecture should be reviewed with Regal's security team as part of your evaluation.
Yes. Regal's Authenticate Contact Action handles real-time identity verification during a call, checking caller responses against stored contact attributes before the agent proceeds to protected actions. The verification step is isolated from broader data access, making it suitable for regulated environments.
No. Regal integrates with Salesforce, HubSpot, and 40+ other platforms with field-level sync configuration. You control which contact attributes sync, and you can limit the sync to only the fields needed for the AI agent's tasks (e.g., account ID, campaign flag, appointment status).
AI agents in HIPAA-regulated deployments are typically designed with a selective data retrieval model: PHI is retrieved via Custom Actions mid-conversation rather than preloaded. Call recordings and transcripts are stored in compliance with your data retention policies.
Post-call, Regal stores call recordings, transcripts, and Custom AI Analysis outputs. These can be configured for your data retention requirements. For regulated industries, Regal's security team can advise on specific configurations.


.webp)
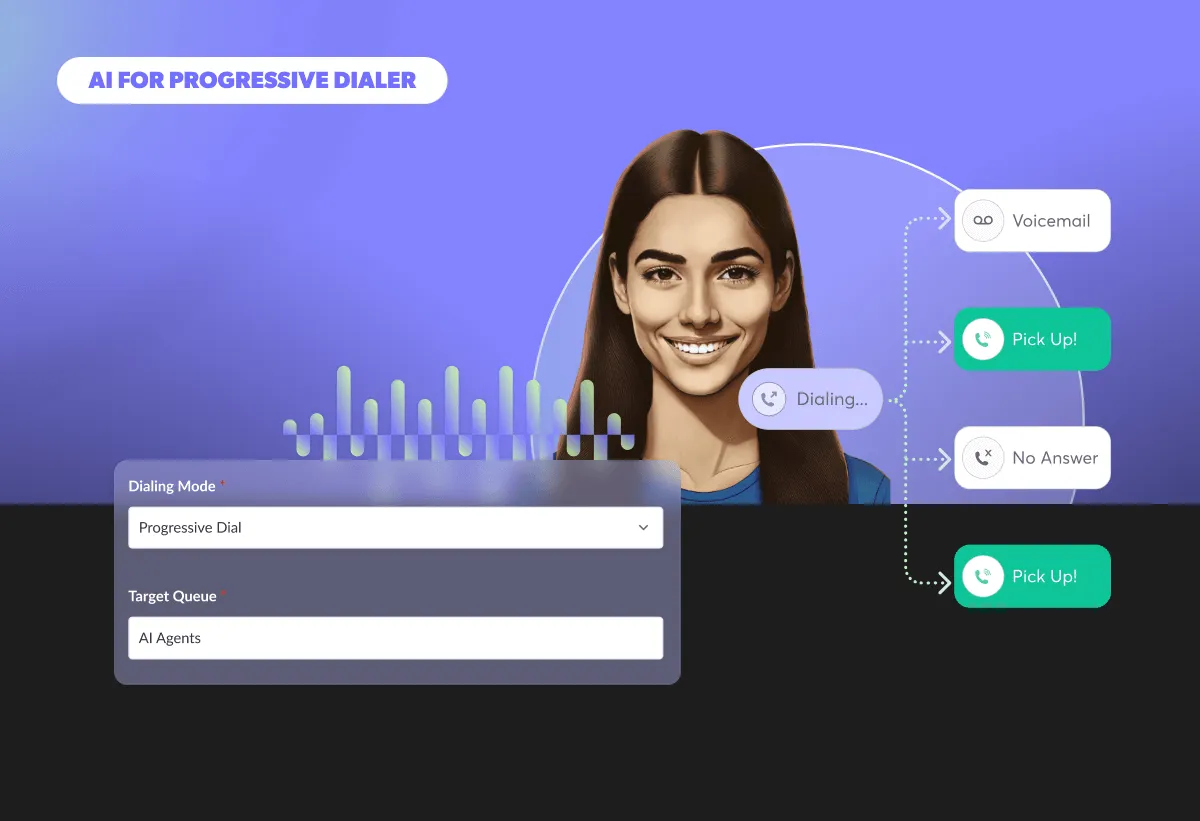
With AI agents, every appointment gets a confirmation call. Each contact gets a chance to reschedule, and the confirmation rate goes to 100%, not because the AI is better at conversations than your agents, but because the AI never runs out of capacity.

The fastest growing High Consideration brands have invested heavily in outbound call centers for sales and marketing. With the right technology, staffing and measurement, you too can build a high performing outbound call center to help hit your growth goals.
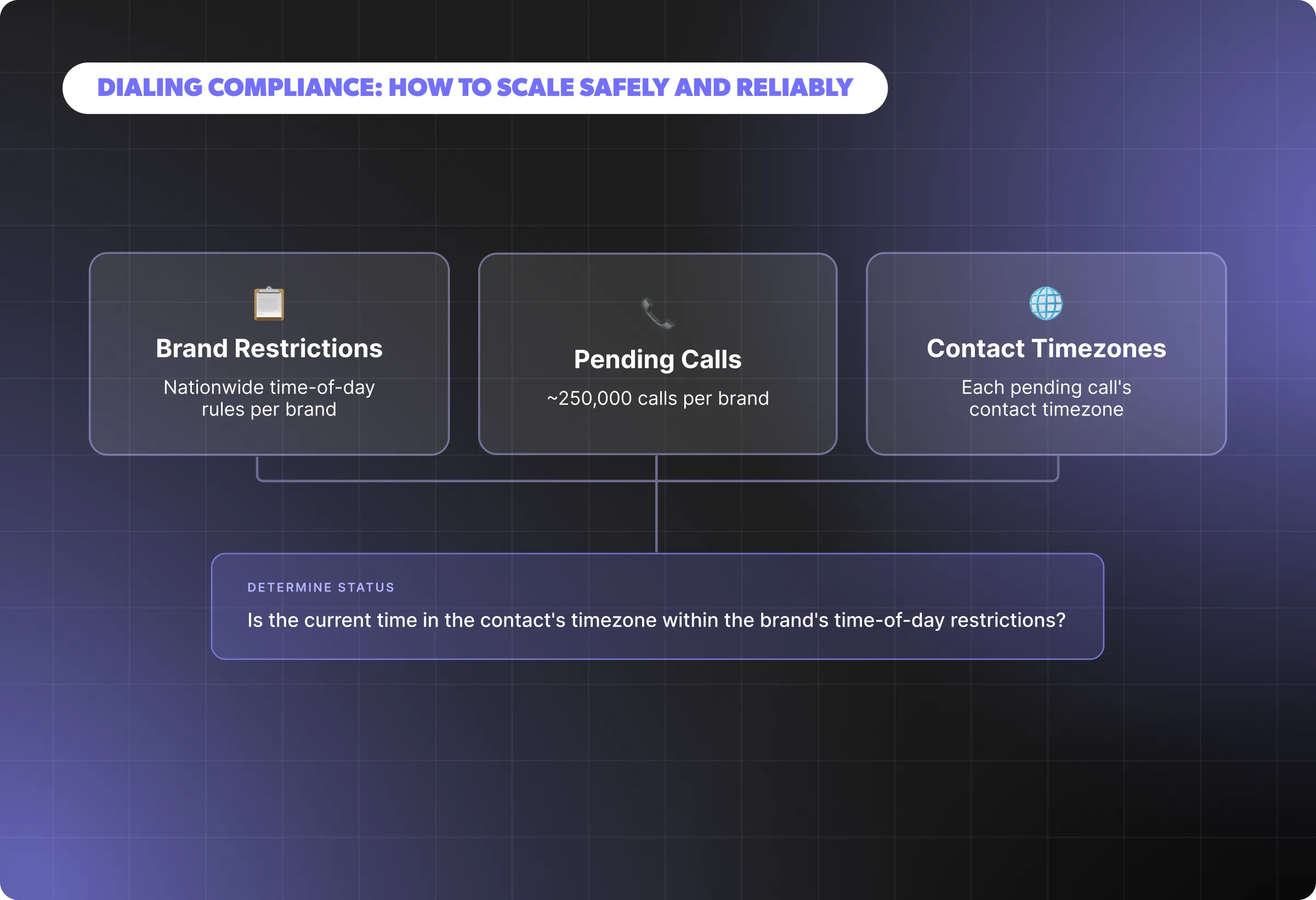
Behind a fragmented and ever-changing regulatory landscape is a simple goal: protecting people from unwanted or poorly timed outreach and giving them control over how they’re contacted. In practice, that responsibility translates into a set of checks that must be validated.

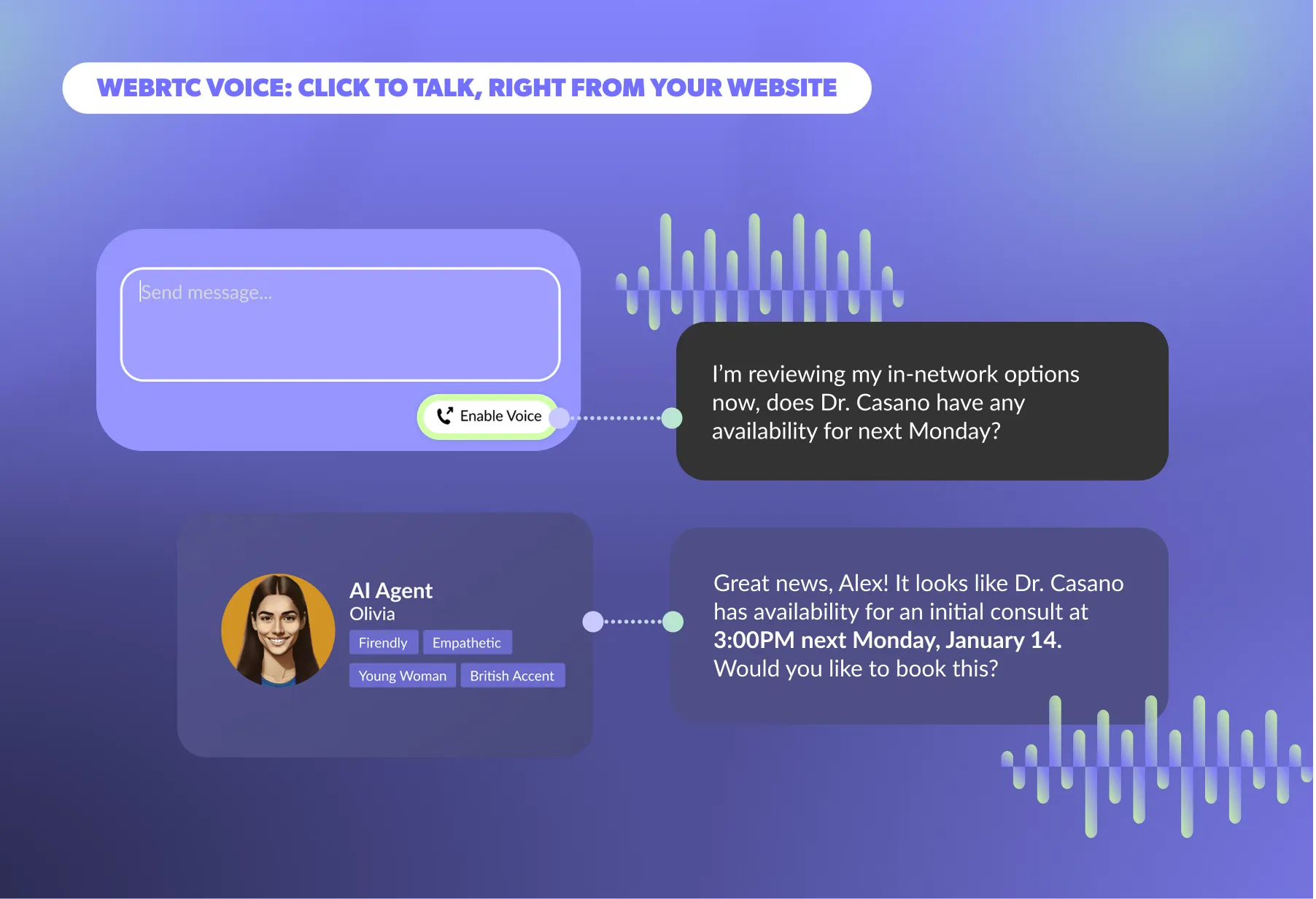
AI phone agents aren't just better phone trees. They are autonomous systems that can understand caller intent, retrieve relevant information from your CRM in real time, execute actions, handle objections and clarifications, and complete the conversation without human involvement.

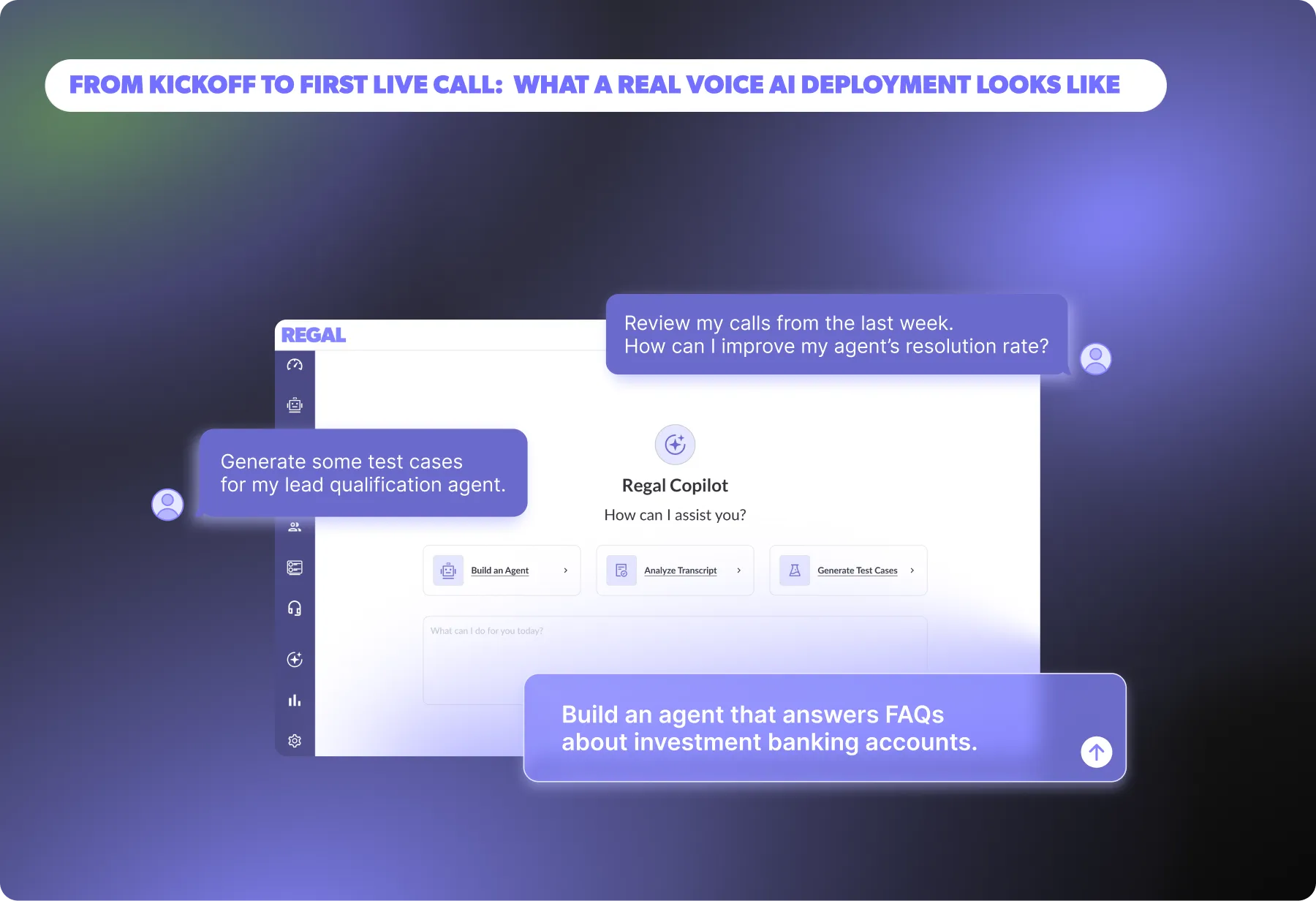
In March, we made it faster than ever to build, launch, and continuously improve AI agents with Copilot, Regal's AI agent for building AI agents. Together, these updates lessen the time needed to launch and maintain agents, so you can focus on understanding your customers, unlocking new use cases, and driving faster business outcomes.
.webp)
AI agent performance depends on how well it aligns with real customer language, not just fluency. Regal Improve helps teams identify gaps and improve outcomes by analyzing real conversations and surfacing high-impact opportunities
.webp)
In this fireside chat, Regal Co-Founder & CEO Alex Levin sits down with Kin Insurance’s Austin Ewell and a360inc’s Henry Davidson to share how their organizations are using AI agents to transform outreach, customer experience, and operational efficiency. They discuss real-world deployments—from qualification and human agent handoffs to complex negotiation workflows—break down the results, and offer practical guidance for leaders adopting AI agents at scale.
.webp)
Learn about the difference between single-state and multi-state AI agents, and how each impacts speed, scale, and reliability. Discover when simplicity is enough and when enterprise workflows demand structured orchestration, so you can choose the right design for your use case.
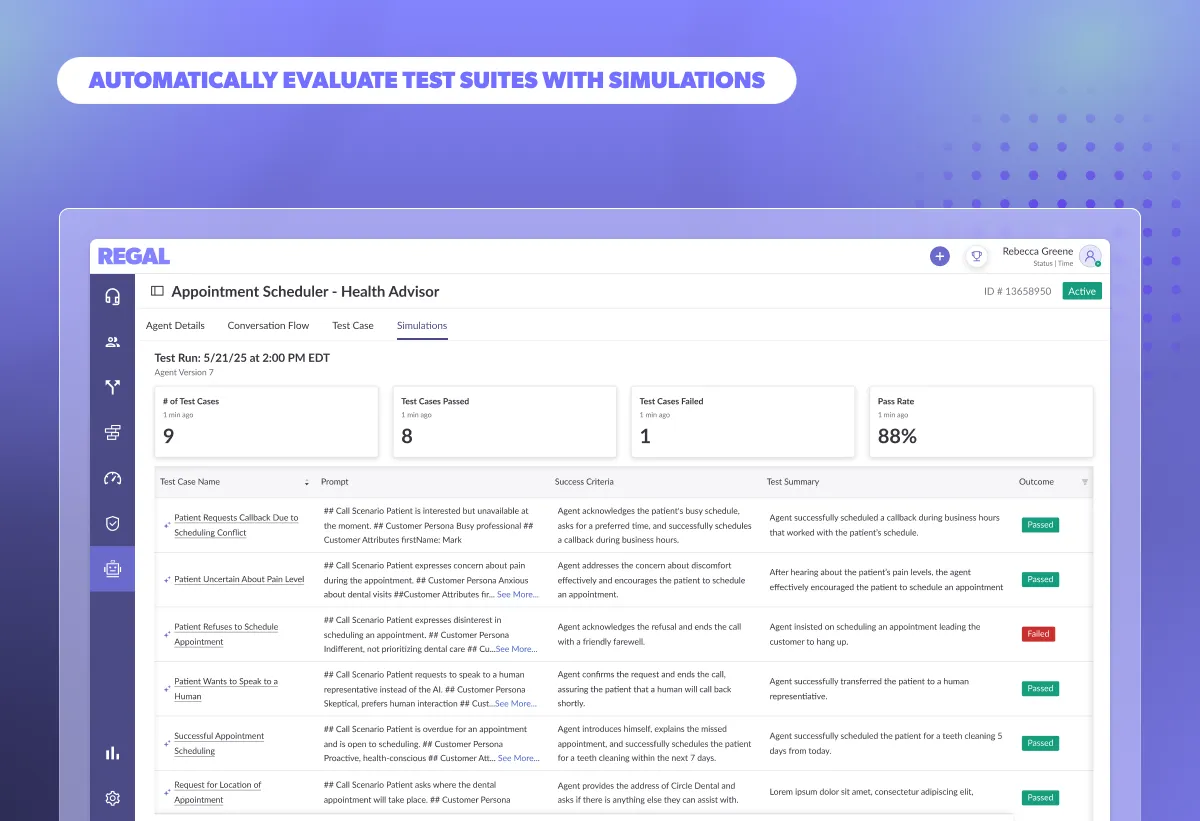
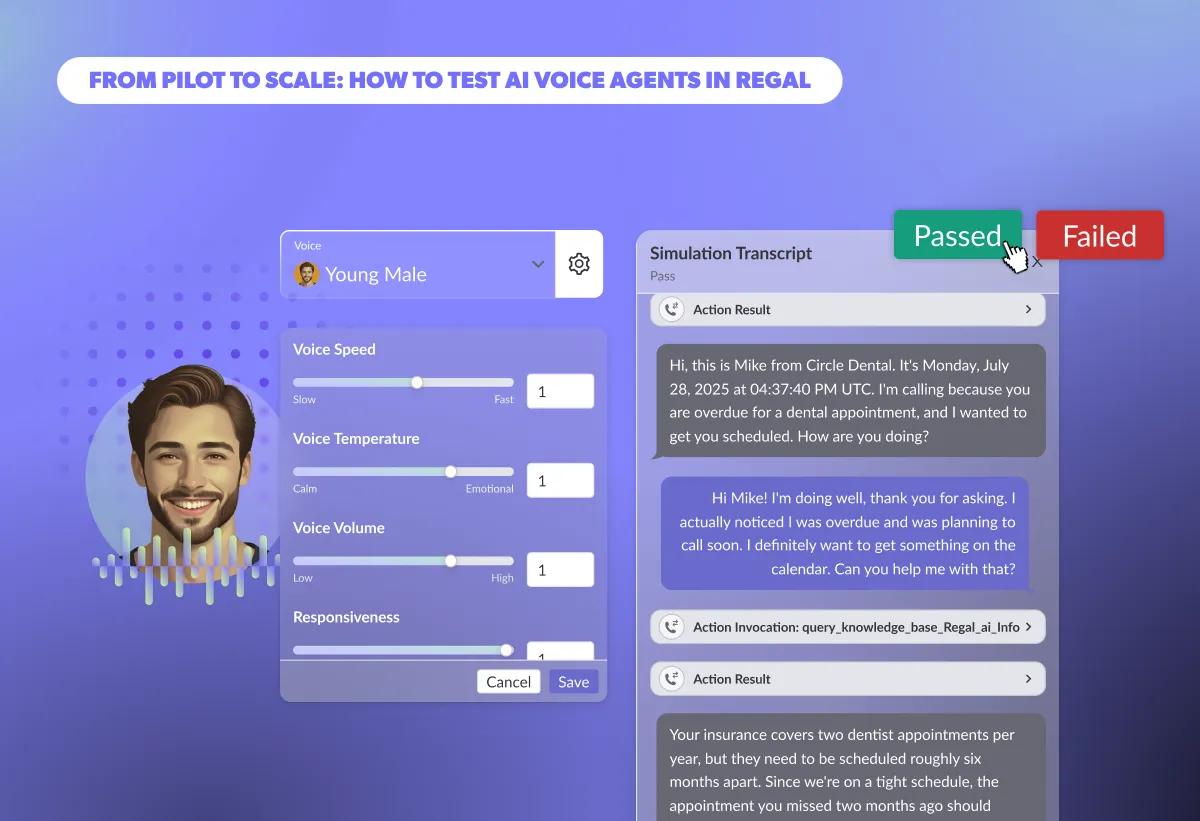
Discover how you can use Simulations to evaluate scenario-specific conversational flows that pinpoint AI Agent failures before launch. Speed up regression testing, validate prompts, knowledge bases, and custom actions at scale, and deploy reliable AI Agents with confidence.
%20(1).webp)
Apple’s iOS 26 introduces new call-screening controls that will reshape outbound performance. This guide explains what’s changing, how adoption may impact enterprise contact centers, and the proactive steps leaders can take now to protect answer rates and customer trust.
Learn how to maintain a clean, reliable RAG system for AI Agents. Discover best practices for structuring source docs, chunking content, titling for retrieval, avoiding redundancy, and keeping knowledge bases fresh to ensure accurate, scalable performance.
.webp)
This article outlines the core characteristics that influence how voice AI is perceived on live calls. From mechanical traits like speed and volume, to more emotional and conversational behaviors, we’re going to look at what those characteristics mean, why they matter, and how they impact your bottom line.
.webp)
Learn how to configure your AI Voice Agent for real performance. This guide covers the most important voice settings in Regal, what ranges top brands use in production, and how adjusting speed, tone, and responsiveness impact cost, containment, and overall customer experience.

AI Agents for Education are transforming student engagement—boosting enrollment, improving retention, and making support more human. Discover 8 game-changing use cases that free up your staff while delivering better student outcomes.

Regal is officially one of Forbes America’s Best Startup Employers 2025, ranking #164 out of 500. This recognition is a testament to our incredible team, our innovative work culture, and our unwavering commitment to advancing AI technology.

AI in education is helping to streamline admissions, automate student engagement, and enhance higher ed outreach. Discover key education technology trends to boost enrollment and learn why automated student engagement tools are the future.
.webp)
When it comes to comparing AI Agents vs. AI Assistants, Siri & Alexa handle simple tasks, but Gen AI Voice Agents—like Regal’s AI Phone Agent—drive real business impact with human-like conversations, automation, and seamless integration.

As AI technology continues to evolve, the use cases for AI Voice Agents in contact centers will only increase. By answering these six key questions, you can identify where AI agents fit best today in your contact center and plan for future integrations.

Consumer businesses are implementing AI-enabled customer experiences without any change in behavior on the part of consumers, which is leading AI to become common with more speed than past transitions like the internet and the smartphone. And it means that the next step in AI will not come from the LLM providers. The next big step forward in AI rests in the hands of consumer businesses.

Explore Eric Hauser's remarkable career journey from GovTech to healthcare disruption at Cadence, highlighting the transformative power of innovation, collaboration, with a special focus on the pivotal role of Regal in driving patient engagement and outcomes.

Discover how Regal.io's AI-powered personalized outreach solutions are revolutionizing outbound sales and customer experience across industries like healthcare, finance, and insurance in our latest eBook, "Modernizing Outbound Contact Centers: How to Treat Millions of Customers like One in a Million."
.jpeg)
Combining collaboration functionality into CCaaS workflow tools invites more cross-functional users from a company to participate in designing the end-customer experience, leading to better omni-channel orchestration and customer outcomes. Learn more about Regal's collaboration features.
Ready to see Regal in action?
Book a personalized demo.




.avif)
.webp)


.webp)
.webp)
.webp)

.webp)
.webp)
.webp)

.avif)


.webp)


.webp)


.webp)
.webp)

.webp)


%20(1).webp)
.webp)
%20(1).webp)
.png)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)
%20(1).webp)
%20(1).webp)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)

.webp)


%202.webp)


.webp)
.webp)
.webp)
.webp)











.avif)






