
SEPTEMBER 2023 RELEASES
September 2023 Releases
Every day, enterprises deploy AI agents to handle thousands of customer interactions, resulting in massive volumes of conversational data, rich with signals about what customers want, where they’re getting stuck, and how the agent is performing overall.
Extracting those insights is incredibly difficult, however.
The way people speak is inconsistent and imprecise, making it nearly impossible to group related conversations using strict keyword matching. Similar ideas can be phrased in dozens of different ways. Without bringing structure to the data, patterns stay hidden.
As a result, transcript data remains one of the most underused sources of learning for improving AI agent performance. It also serves as a powerful form of business intelligence, revealing what customers need, want, and object to at scale.
While managers and operators can review some calls manually, it’s simply not possible for anyone to listen or even read through every transcript.
Incomplete review leads to missed insights, which leads to missed opportunities for improving customer experiences and optimizing your AI agent’s performance.
To tackle this challenge, we've developed a streamlined approach to automatically extract and understand meaningful customer moments from transcripts.
By leveraging advanced LLMs like GPT-4o mini, we pinpoint crucial moments from every call (customer questions, objections, reasons for calling, etc.).
We then enrich them with essential context, making each statement independently clear and insightful.
These enriched conversational moments are then converted into numerical embeddings using AWS Titan V2, allowing us to identify hidden patterns and conversation themes through sophisticated clustering techniques like Uniform Manifold Approximation Projection (UMAP) and Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN).
Finally, we use GPT-4.1 to clearly label these clusters, translating dense data into intuitive, human-readable, business-friendly insights.
%201%20(2)%20(1).png)
The end result?
You gain rapid clarity on customer concerns and interests, enabling smarter decisions and more meaningful customer interactions.
To bring this process to life, we’ll follow a real transcript from Regal’s inbound AI agent, Reggie.
As we go through each step of the process below, I’ll refer back to this transcript to show examples of how it’s transformed into structured, actionable insights.
For context, Reggie is an enthusiastic AI agent we use at Regal to introduce our value proposition to customers and prospects.
Reggie answers common questions, and engages with users in a Regal-branded way.
Here is the transcript between Reggie and a Regal customer:
To ensure our input conversation transcripts are reliable we start by aggregating moments into a turn-by-turn, speaker role-based transcript with the help of a DBT model to create a Snowflake table as our input.
To reduce noise or false insights, we only analyze transcripts that have at least four conversational turns, where genuine interaction occurred according to call disposition data, excluding any dialogue after the AI agent transfers the call.
Then, we employ GPT-4o mini to pinpoint and enrich key moments such as customer questions, objections, reasons for initiating contact, and decisions.
This careful extraction ensures we focus on valuable exchanges rather than routine interactions.
Each extraction falls into one of these categories:
We specifically tell the AI to discard:
This filtering ensures that we only focus on rich, actionable moments in the conversation.
After extraction, we instruct the AI to enrich each moment by adding relevant context from surrounding parts of the conversation.
Each enriched moment provides clear, standalone context that transforms extensive conversational data into easy-to-understand, actionable insights, making it straightforward for your org to respond effectively.
Let's revisit our earlier example with our AI agent, Reggie, speaking to Sean, Tom, and Vanessa.
From their conversation, GPT-4o mini helps us identify and clearly articulate critical customer moments and what category each moment lives.
{ "extraction_number": 1,
"category": "reason",
"enriched_moment": "looking to use a technology like Regal AI to enable help desk agents support customers more efficiently" },
{ "extraction_number": 2,
"category": "question",
"enriched_moment": "can we integrate our specific data, do you integrate with 8x8?" },
{ "extraction_number": 3, "category": "question",
"enriched_moment": "Is it accurate your pricing is around 10 to 25 cents a minute?" },
{ "extraction_number": 4, "category": "objection",
"enriched_moment": "the process to implement AI seems too difficult, I don't think we are ready" }After we identify and enrich meaningful moments from conversations, we need to translate these text-based insights into something computers can easily understand.
In this case, we turn them into numerical embeddings.
Think of embeddings as coordinates on a map: Where similar ideas and phrases land close to each other, making it simple for algorithms to spot similarities (and therefore patterns) between similar data points.
We use a powerful embedding model called AWS Titan V2 to transform each enriched conversational moment into a dense numerical representation.
Imagine phrases like "refund delayed" and "why is my refund late?"
Even though these phrases are slightly different in language, they’ll end up close to each other in the embedding space because their meanings overlap.
Consider singular words “dog” and “puppy.” Let’s turn them into numbers. At a high level, the text gets tokenized, meaning puppy is split into “pup” and “###py.”
We then map these tokens to vectors and refine them by looking at surrounding tokens. These vectors are pooled and normalized to create ‘embeddings’:
Each position (dimension) is a learned feature discovered by the model during training. These dimensions don’t have neat human labels, but you can think of them as abstract gauges the model dials up or down.
You can probe them, but they’re best treated as coordinates where distance encodes meaning. To build intuition, here’s a fictional abstraction of the first three dimensions:
.png)
Each individual word here has seven dimensions. As you can imagine, those dimensions build greater meaning and compound when words are put together in a full sentence.
When embedding an entire sentence, a vector can have upwards of 1,000 dimensions. You can’t visualize 7D (let alone 1,000D).
Since these embeddings get so complex, we use dimensionality reduction techniques (like UMAP) to project the embeddings into 2D diagrams that preserve local neighborhoods (i.e. preserve essential information).
Distances and clumps reflect semantic similarity, not human-named axes. For example in the above plot, if a vector connecting “man” to “woman” captures a gender relation, a similar offset might connect “king” to “queen.”
We simplify these embeddings into a smaller N-dimensional space from the origin, which makes broader patterns easier to spot for our clustering algorithm.
Let's take one moment from Reggie’s conversation, this Customer Question:
"Can we integrate our specific data… Do you integrate with 8x8?"
A sentence embedding is going to be richer than a single word because the The AWS Titan V2 model encodes all tokens together, letting words shape each other’s meaning.
In this example, “Integrate” shifts toward “software/platform interoperability” because it co-occurs with “data” and the vendor entity “8x8” (a communications platform).
The pooled output becomes one vector (e.g., 1,024-D from Titan V2) that captures intent (“integration request”), entities (8x8), and topic (data/system interoperability), not just isolated words.
That’s why a sentence embedding is richer: It represents meaning, intent, and topics, and brings context to phrasing, which is exactly what we want for clustering conversational moments.
Our example would generate numbers as represented below. In this case, we show the first 20 dimensions out of a total of 1,024:
[0.23, -0.17, 0.34, 0.89, -0.56,
0.12, -0.44, 0.67, 0.09, -0.31,
-0.78, 0.24, 0.85, -0.26, 0.19,
-0.14, 0.94, 0.19, -0.36, ...]
(up to 1,024 dimensions total)
UMAP simplifies the above embedding instead into:
[0.45, -0.29, 0.74, -0.03, 0.52]
This UMAP reduction starts by building a neighbor graph in 1,024-D. Within those dimensions, it finds five new axes that preserve all the essential information (i.e. neighborhoods).
Those five coordinates don’t have fixed semantic labels; instead, they become the new axes that best maintain the closeness of other embeddings.
This reduced representation produces enough capacity for clustering (HDBSCAN), while dropping noisy or redundant variance.
Once we've converted conversations into simplified numerical representations, the next challenge is discovering meaningful patterns.
This is where clustering comes into play.
We utilize a powerful algorithm called HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) to identify patterns.
Unlike traditional methods that require us to specify the number of topics beforehand, HDBSCAN automatically finds natural groupings by identifying dense pockets of similar conversation moments.
Think of it as a way of spotting busy neighborhoods (clusters) and lonely outliers (noise) on a map.
To ensure groupings are meaningful, we can control and optimize this algorithm with parameters such as:
As a result, we're able to uncover real, significant patterns whether customers repeatedly question pricing, express concerns about implementation, or frequently inquire about integration capabilities.
Let's revisit our example with Reggie and imagine we have extracted conversational moments from all of Reggie's conversations, not just with Sean, Tom, and Vanessa. Then we converted those conversations into embeddings, then visualized them as points.
HDBSCAN might group their questions about data integration and pricing closely together, showing these as prevalent, common topics.
Conversely, the isolated moment where they express concerns about AI implementation might be identified as noise (if few other customers raised similar concerns).
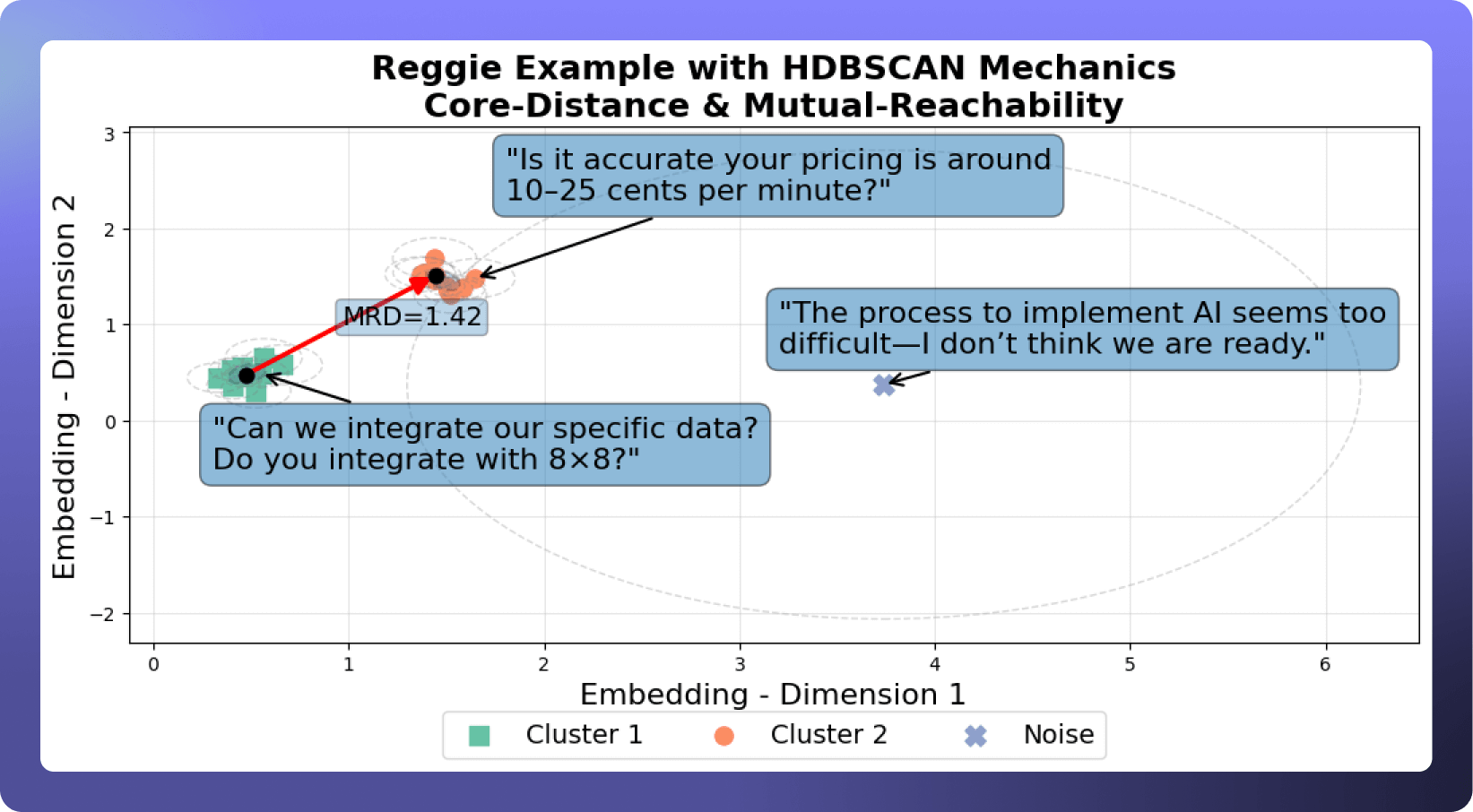
Visualization Key:
Identifying clusters is powerful, but translating them into actionable insights requires further clarification.
This is where GPT-4.1 steps in, transforming all these groupings into intuitive labels and concise descriptions that anyone in your organization can easily understand.
For each identified cluster, we take representative conversational moments along with our defined "Agent Goal" (what the AI is trying to achieve during interactions) and instruct GPT-4.1 to craft clear, relevant labels.
Each label succinctly summarizes the underlying theme or customer concern of that cluster. To further simplify interpretation, we organize these individual labels into broader "parent topics."
For instance, detailed questions or comments about pricing (e.g. “Are there fees associated with integration?” or “That fee seems high for what we can afford”) can be grouped under the broader parent topic of "Pricing & Cost Concerns."
This hierarchical approach enables you to quickly grasp overarching themes and see, at a glance, what customers frequently discuss or express concern about—and take meaningful action to address those concerns.
Okay so, back to Reggie's conversation with Sean, Tom, and Vanessa. After clustering, here's how GPT-4.1 might label each meaningful conversational moment:
.png)
Turning complex conversational data into actionable insights is the ultimate goal here.
Clearly labeled clusters, enriched with context and grouped into intuitive topics, empower you to make informed, strategic decisions quickly.
We tie conversational topics to configurable success metrics like conversation duration, sentiment analysis scores, and call transfer rates, so you can identify which types of conversations need work and proactively take action to fix them through prompt or Knowledge Base updates.
In order to consume these insights, it's important the data is structured in a manner which makes key information readily available.
This output is written back to Snowflake, where all the rich conversational intelligence we’ve extracted and labeled comes together in a business-friendly format. This table serves as the single source of truth that your organization can consume, analyze, and act on.
Each row in the table represents a meaningful moment from a conversation, enriched, categorized, and clustered for easy interpretation. Here are the key fields that brands care about:
.png)
Teams can analyze these fields to:
For example:
Using our Reggie clusters, we see that calls where Regal prospects ask about integration with 8x8 have higher-than-average call durations and negative customer sentiment.
We then dig into those transcripts and notice the AI Agent isn’t providing clear integration steps or addressing data security concerns. That signals the opportunity to update the AI Agent’s objection handling to cover those points directly, and expand the knowledge base with detailed integration instructions and security information so the agent can surface them in real time.
To enable consumption of this data, we have created the Knowledge Base and Conversation Insights Dashboard, offering an intuitive and interactive way to consume conversational insights.
At the top we provide a quick summary of conversation volumes and topic counts, highlighting the most frequently discussed parent and sub-topics. At a glance, you’re able to see what’s top-of-mind for your customers.
Then we use bubble charts to represent the top conversation categories, Reasons/Decisions, Objections, and Questions.
.png)
The size of each bubble shows topic prevalence, so you can clearly pinpoint prominent customer concerns or inquiries. Then, the color overlays a configurable performance metric (like transfer rate for our sales agent Reggie) to show how each conversational topic is performing relative to others.
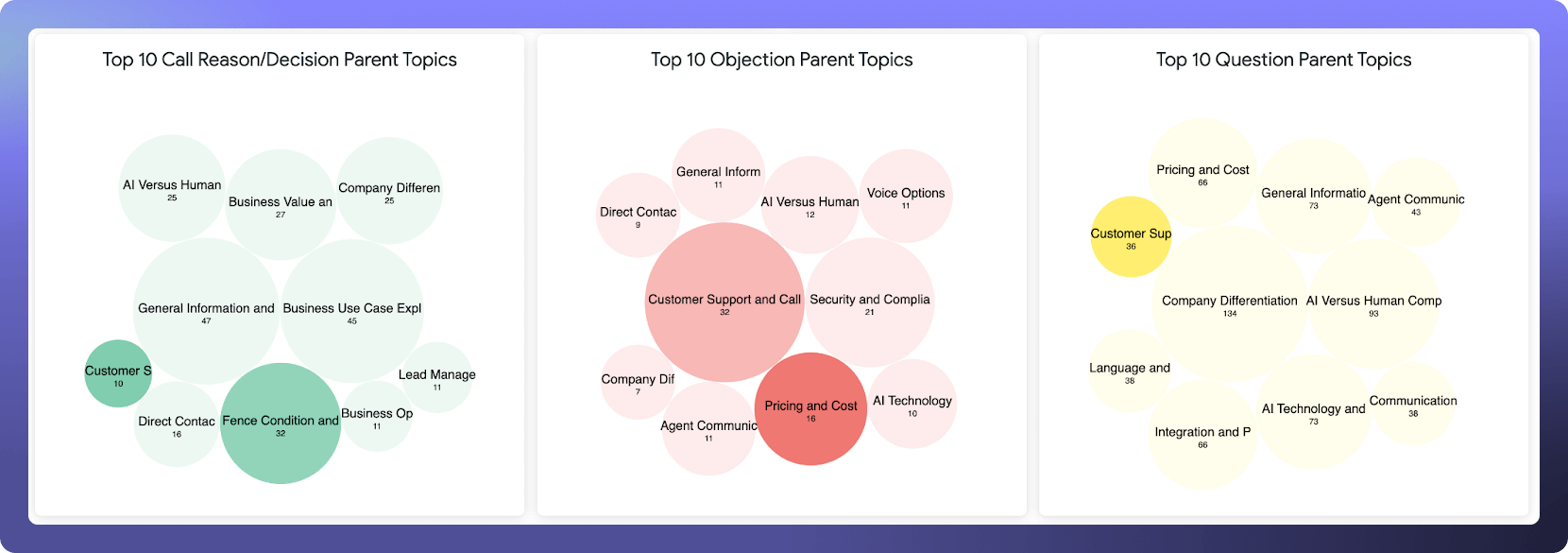
Finally, the detailed breakdown table connects topics and sub-topics with critical metrics like transfer rate, conversation counts, and type distributions (e.g., objections or questions).
With this view, you’ll know exactly what conversations to drill into first to start troubleshooting.
That could be:
.png)
Ultimately, transforming conversations into insights isn't just about understanding data, it's about truly understanding your customers and empowering your business to act with clarity and confidence.
From the image above, you might spot that “Company Differentiation and Reputation” has the highest overall volume, that 41% of “Customer Support and Call Handling” moments are objections, or that topics like “AI Technology and Architecture” are dominated by technical questions.
Each of these signals where your attention should be focused most often, and also signals different opportunities—whether that’s strengthening objection handling or expanding your knowledge base to better cover high-interest areas.
One of the most compelling advantages of embedding conversational moments is enabling semantic search across an entire set of interactions.
For example, in a dashboard you search: "frustrated about long wait times." The query is passed through the same embedding model, transforming it into a vector.
We then search for the closest vectors in our database of conversation embeddings, surfacing the most semantically similar moments, even if the customer never used the exact phrase “long wait.”
This allows you to instantly:
Whether you want to find examples of people who are ready to convert, expressing confusion, or strongly objecting, you can now find them with natural language queries.
Another powerful application of semantic embeddings is evaluating how effectively an AI agent's knowledge base covers frequently discussed customer topics.
For example, if many customers inquire about integrating with a CRM, but few similar embeddings appear in the knowledge base, this signals an actionable gap, which could prompt updates or expansions to agent knowledge databases.
Embedding and clustering customer conversations also allows you to track net new clusters and analyze shifts in embedding patterns over time.
This makes it possible to detect shifts in customer interest or concerns at an early stage.
For instance, if a new cluster of inquiries around AI ethics or data privacy emerges, you can quickly create relevant Knowledge Base content or adjust AI Agent prompts to address these concerns head-on, before they become widespread issues.
The challenge we started with was clear… Massive volumes of AI-handled conversations are filled with valuable customer signals that are buried in unstructured transcripts too large to review manually.
With Regal, every interaction becomes structured, enriched, and transformed into a format machines can understand, without losing the nuance humans need to gain insights and optimize AI agent performance.
By bridging raw language and actionable data, you move from guesswork to precision, from missed opportunities to targeted improvements.
The result is what we and every enterprise hopes to gain with AI: faster insight, smarter decisions, and customer interactions that keep getting better.


.png)
In this fireside chat, Regal Co-Founder & CEO Alex Levin sits down with Kin Insurance’s Austin Ewell and a360inc’s Henry Davidson to share how their organizations are using AI agents to transform outreach, customer experience, and operational efficiency. They discuss real-world deployments—from qualification and human agent handoffs to complex negotiation workflows—break down the results, and offer practical guidance for leaders adopting AI agents at scale.
.png)
Learn about the difference between single-state and multi-state AI agents, and how each impacts speed, scale, and reliability. Discover when simplicity is enough and when enterprise workflows demand structured orchestration, so you can choose the right design for your use case.

Discover how you can use Simulations to evaluate scenario-specific conversational flows that pinpoint AI Agent failures before launch. Speed up regression testing, validate prompts, knowledge bases, and custom actions at scale, and deploy reliable AI Agents with confidence.
%20(1).png)
Apple’s iOS 26 introduces new call-screening controls that will reshape outbound performance. This guide explains what’s changing, how adoption may impact enterprise contact centers, and the proactive steps leaders can take now to protect answer rates and customer trust.
Learn how to maintain a clean, reliable RAG system for AI Agents. Discover best practices for structuring source docs, chunking content, titling for retrieval, avoiding redundancy, and keeping knowledge bases fresh to ensure accurate, scalable performance.
.png)
This article outlines the core characteristics that influence how voice AI is perceived on live calls. From mechanical traits like speed and volume, to more emotional and conversational behaviors, we’re going to look at what those characteristics mean, why they matter, and how they impact your bottom line.
.png)
Learn how to configure your AI Voice Agent for real performance. This guide covers the most important voice settings in Regal, what ranges top brands use in production, and how adjusting speed, tone, and responsiveness impact cost, containment, and overall customer experience.

AI Agents for Education are transforming student engagement—boosting enrollment, improving retention, and making support more human. Discover 8 game-changing use cases that free up your staff while delivering better student outcomes.

Regal is officially one of Forbes America’s Best Startup Employers 2025, ranking #164 out of 500. This recognition is a testament to our incredible team, our innovative work culture, and our unwavering commitment to advancing AI technology.

AI in education is helping to streamline admissions, automate student engagement, and enhance higher ed outreach. Discover key education technology trends to boost enrollment and learn why automated student engagement tools are the future.
.webp)
When it comes to comparing AI Agents vs. AI Assistants, Siri & Alexa handle simple tasks, but Gen AI Voice Agents—like Regal’s AI Phone Agent—drive real business impact with human-like conversations, automation, and seamless integration.

As AI technology continues to evolve, the use cases for AI Voice Agents in contact centers will only increase. By answering these six key questions, you can identify where AI agents fit best today in your contact center and plan for future integrations.

Consumer businesses are implementing AI-enabled customer experiences without any change in behavior on the part of consumers, which is leading AI to become common with more speed than past transitions like the internet and the smartphone. And it means that the next step in AI will not come from the LLM providers. The next big step forward in AI rests in the hands of consumer businesses.

Explore Eric Hauser's remarkable career journey from GovTech to healthcare disruption at Cadence, highlighting the transformative power of innovation, collaboration, with a special focus on the pivotal role of Regal in driving patient engagement and outcomes.

Discover how Regal.io's AI-powered personalized outreach solutions are revolutionizing outbound sales and customer experience across industries like healthcare, finance, and insurance in our latest eBook, "Modernizing Outbound Contact Centers: How to Treat Millions of Customers like One in a Million."
.jpeg)
Combining collaboration functionality into CCaaS workflow tools invites more cross-functional users from a company to participate in designing the end-customer experience, leading to better omni-channel orchestration and customer outcomes. Learn more about Regal's collaboration features.

Jon Heaps, former VP, Channel at Observe.ai, Talkdesk, and inContact interviews Alex Levin, Co-Founder & CEO of Regal.io, about the history of the contact center industry and some of the key challenges teams making outbound calls face as customers demand more online experiences.

Are you using Branded Caller ID for outbound calls or SMS? New SMS and Branded Caller ID regulations rolled out in Q2 2023 that you MUST KNOW ABOUT. The new regulations require that every company register their SMS campaigns and Branded Caller ID campaigns before being allowed to send texts or brand calls.

Regal’s Conversation Intelligence drives higher conversion rates for B2C sales teams. We use both the traditional QA/coaching tools, and brand new conversational triggers that allow you to update customer profiles and send automated follow up messages based on what is said in a conversation.

We are excited to announce Regal Call Branding™ including Branded Caller ID. Available on all 400M wireless devices in the US (as well as most of Canada and the UK), Regal Call Branding™ puts you in control of what people see when you call their cell phone – including showing your brand and/or logo.

Get behind-the-scenes insights about Perry Health’s 23% revenue increase with Regal.io. Perry Health’s Scott Chesrown sat down with Regal.io and discussed how they implemented outbound sales technology, integrated new capabilities into their process, and built on their early success.

It’s the holiday season and you’d like to hit your December revenue goals. Outbound B2C sales during the holidays can be a major performance driver – if you're prepared and you have the right tools in place. Use these seven tips to get your outbound B2C sales in shape for holiday success.
.png)
Learn how to structure a knowledge base that keeps AI Agents accurate and on-script. Discover why human-style KBs fail, and apply best practices like single-topic chunking, concrete instructions, and explicit outcomes to reduce hallucinations and scale reliable RAG performance.
Ready to see Regal in action?
Book a personalized demo.










.webp)


.png)


.png)

.png)

.png)



%20(1).png)
.png)
%20(1).png)
.png)
.webp)
.webp)
.webp)
.webp)
%20(1).png)
%20(1).png)
%20(1).webp)
.webp)
.webp)
.webp)
.webp)
%20(1).webp)

.webp)


%202.webp)


.webp)
.webp)
.webp)
.webp)











.avif)





















